Introduction
In the rapidly evolving digital world, businesses are always looking for ways to optimize processes, minimize manual tasks, and boost overall efficiency. For those that depend on job scheduling and workload automation, Control-M from BMC Software has been a reliable tool for years. Now, with the arrival of the Control-M Automation API, organizations can elevate their automation strategies even further. In this blog post, we’ll delve into what the Control-M Automation API offers, the advantages it brings, and how it can help revolutionize IT operations.
What is the Control-M Automation API?
The Control-M Automation API from BMC Software demonstrates how developers can use Control-M to automate workload scheduling and management. Built on a RESTful architecture, the API enables an API-first, decentralized method for building, testing, and deploying jobs and workflows. It offers services for managing job definitions, deploying packages, provisioning agents, and setting up host groups, facilitating seamless integration with various tools and workflows.
With the API, you can:
- Streamline job submission, tracking, and control through automation.
- Connect Control-M seamlessly with DevOps tools such as Jenkins, GitLab, and Ansible.
- Develop customized workflows and applications to meet specific business requirements.
- Access real-time insights and analytics to support informed decision-making.
Key Benefits of Using Control-M Automation API
- Infrastructure-as-Code (IaC) for Workload Automation
Enables users to define jobs as code using JSON, allowing for version control and better collaboration. It also supports automation through GitOps workflows, making workload automation an integral part of CI/CD pipelines.
- RESTful API for Programmatic Job Management
Provides a RESTful API to create, update, delete, and monitor jobs from any programming language (Python, Java, PowerShell, etc.). It allows teams to automate workflows without relying on a graphical interface, enabling CI/CD integration and process automation.
- Enhanced Automation Capabilities
By leveraging the Control-M Automation API, organizations can automate routine tasks, decreasing reliance on manual processes and mitigating the potential for human error. This capability is particularly valuable for managing intricate, high-volume workflows.
- Seamless Integration
By serving as a bridge between Control-M and external tools, the Control-M Automation API enables effortless integration with CI/CD pipelines, cloud services, and third-party applications—streamlining workflows into a unified automation environment.
- Improved Agility
Through Control-M Automation API integration, organizations gain the flexibility to accelerate application deployments and dynamically scale operations, ensuring responsive adaptation to market changes.
- Real-Time Monitoring and Reporting
The Control-M Automation API provides real-time access to job statuses, logs, and performance metrics. This enables proactive monitoring and troubleshooting, ensuring smoother operations.
- Customization and Extensibility
The API provides the building blocks to develop purpose-built solutions matching your exact specifications, including custom visualization interfaces and integration with specialized third-party applications.
Use Cases for Control-M Automation API
- DevOps Integration
Integrate Control-M with your DevOps pipeline to automate the deployment of applications and infrastructure. For example, you can trigger jobs in Control-M from Jenkins or GitLab, ensuring a seamless flow from development to production.
- Cloud Automation
Leverage the Control-M API to handle workloads across hybrid and multi-cloud setups. Streamline resource provisioning through automation, track cloud-based tasks, and maintain adherence to organizational policies.
- Data Pipeline Automation
Automate data ingestion, transformation, and loading processes. The API can be used to trigger ETL jobs, monitor their progress, and ensure data is delivered on time.
- Custom Reporting and Analytics
Extract job data and generate custom reports for stakeholders. The API can be used to build dashboards that provide insights into job performance, SLA adherence, and resource utilization.
- Event-Driven Automation
Set up event-driven workflows where jobs are triggered based on specific conditions or events. For example, you can automate the restart of failed jobs or trigger notifications when a job exceeds its runtime.
Example 1: Scheduling a Job with Python
Here is another example of using the Control-M Automation API to define and deploy a job in Control-M. For this, we’ll use a Python script (you’ll need a Control-M environment with API access set up).
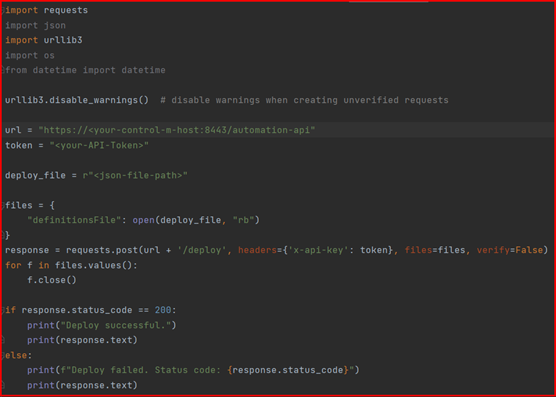
Output of the code shows the successful deployment of jobs/folder in Control-M.
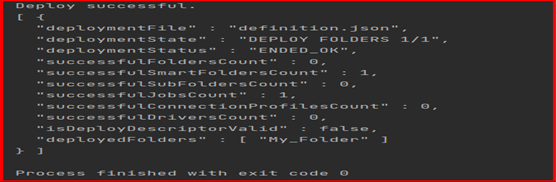
And the folder is successfully deployed in Control-M which can be checked in GUI.

Example 2: Automating Job Submission with Python
Here’s a simple example of how you can use the Control-M Automation API to submit a job using Python:
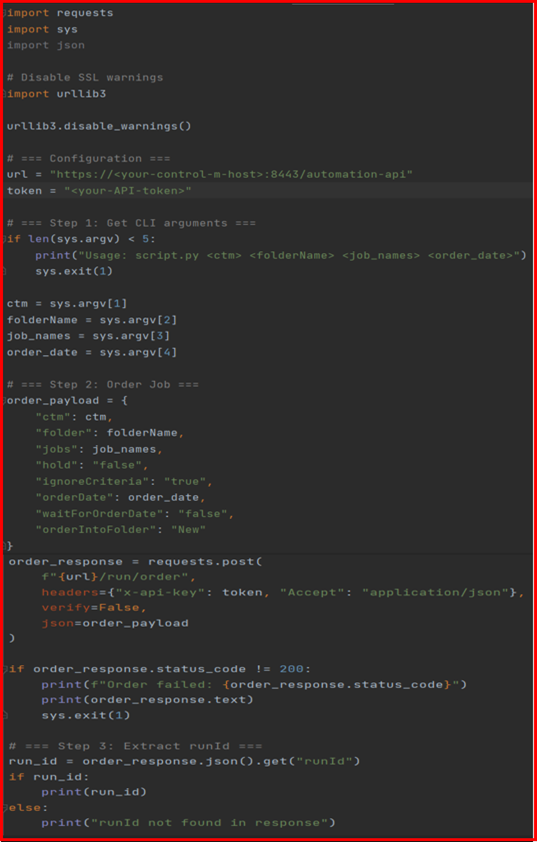
Execute the above Python code and it will return the “RUN ID”.

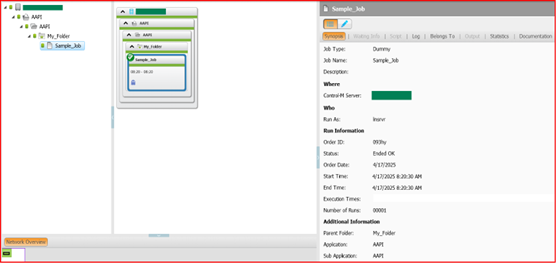
The folder is successfully ordered and executed which can be checked in Control-M GUI.
Getting Started with Control-M Automation API
- Access the API Documentation
BMC provides comprehensive documentation for the Control-M Automation API, including endpoints, parameters, and examples. Familiarize yourself with the documentation to understand the capabilities and limitations of the API.
- Set Up Authentication
The API uses token-based authentication. Generate an API token from the Control-M GUI and use it to authenticate your requests.
- Explore Sample Scripts
BMC offers sample scripts and code snippets in various programming languages (Python, PowerShell, etc.) to help you get started. Use these as a reference to build your own integrations.
- Start with Simple Use Cases
Begin by automating simple tasks, such as job submission or status monitoring. Once you’re comfortable, move on to more complex workflows.
- Leverage Community and Support
Join the BMC community forums to connect with other users, share ideas, and troubleshoot issues. BMC also offers professional support services to assist with implementation.
Conclusion
The Control-M Automation API is a game-changer for organizations looking to enhance their automation capabilities. By enabling seamless integration, real-time monitoring, and custom workflows, the API empowers businesses to achieve greater efficiency and agility. Whether you’re a developer, IT professional, or business leader, now is the time to explore the potential of the Control-M Automation API and unlock new levels of productivity.
]]>BMC & AWS Logo
![]()
Model training and evaluation are fundamental in payment fraud detection because the effectiveness of a machine learning (ML)-based fraud detection system depends on its ability to accurately identify fraudulent transactions while minimizing false positives. Given the high volume, speed, and evolving nature of financial fraud, properly trained and continuously evaluated models are essential for maintaining accuracy and efficiency. Fraud detection requires a scalable, automated, and efficient approach to analyzing vast transaction datasets and identifying fraudulent activities.
This blog presents an ML-powered fraud detection pipeline built on Amazon Web Services (AWS) solutions—Amazon SageMaker, Amazon Redshift, Amazon EKS, and Amazon Athena—and orchestrated using Control-M to ensure seamless automation, scheduling, and workflow management in a production-ready environment. The goal is to train three models—logistic regression, decision tree, and multi-layer perceptron (MLP) classifier across three vectors—precision, recall, and accuracy. The results will help decide which model can be promoted into production.
While model training and evaluation is the outcome, the training and evaluation is part of the larger pipeline. In this blog, the represented pipeline integrates automation at every stage, from data extraction and preprocessing to model training, evaluation, and result visualization. By leveraging Control-M’s orchestration capabilities, the workflow ensures minimal manual intervention, optimized resource utilization, and efficient execution of interdependent jobs.
Process Flow:
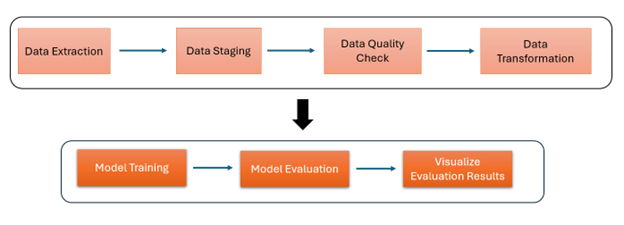
Figure 1. The end-to-end pipeline.
Key architectural highlights include:
- Automated data extraction and movement from Amazon Redshift to Amazon S3 using Control-M Managed File Transfer (MFT)
- Orchestrated data validation and preprocessing with AWS Lambda and Kubernetes (Amazon EKS)
- Automated model training and evaluation in Amazon SageMaker with scalable compute resources
- Scheduled performance monitoring and visualization using Amazon Athena and QuickSight
- End-to-end workflow orchestration with Control-M, enabling fault tolerance, dependency management, and optimized scheduling
In production environments, manual execution of ML pipelines is not feasible due to the complexity of handling large-scale data, model retraining cycles, and continuous monitoring. By integrating Control-M for workflow orchestration, this solution ensures scalability, efficiency, and real-time fraud detection while reducing operational overhead. The blog also discusses best practices, security considerations, and lessons learned to help organizations build and optimize their fraud detection systems with robust automation and orchestration strategies.
Amazon SageMaker:
The core service in this workflow is Amazon SageMaker, AWS’s fully managed ML service, which enables rapid development and deployment of ML models at scale. We’ve automated our ML workflow using Amazon SageMaker Pipelines, which provides a powerful framework for orchestrating complex ML workflows. The result is a fraud detection solution that demonstrates the power of combining AWS’s ML capabilities with its data processing and storage services. This approach not only accelerates development but also ensures scalability and reliability in production environments.
Dataset Overview
The dataset used for this exercise is sourced from Kaggle, offering an excellent foundation for evaluating model performance on real-world-like data.
The Kaggle dataset used for this analysis provides a synthetic representation of financial transactions, designed to replicate real-world complexities while integrating fraudulent behaviors. Derived from the PaySim simulator, which uses aggregated data from financial logs of a mobile money service in an African country, the dataset is an invaluable resource for fraud detection and financial analysis research.
The dataset includes the following features:
- step: Time unit in hours over a simulated period of 30 days.
- type: Transaction types such as CASH-IN, CASH-OUT, DEBIT, PAYMENT, and TRANSFER.
- amount: Transaction value in local currency
- nameOrig: Customer initiating the transaction.
- oldbalanceOrg/newbalanceOrig: Balance before and after the transaction for the initiating customer.
- nameDest: Recipient of the transaction.
- oldbalanceDest/newbalanceDest: Balance before and after the transaction for the recipient.
- isFraud: Identifies transactions involving fraudulent activities.
- isFlaggedFraud: Flags unauthorized large-scale transfers.
Architecture
The pipeline has the following architecture and will be orchestrated using Control-M.
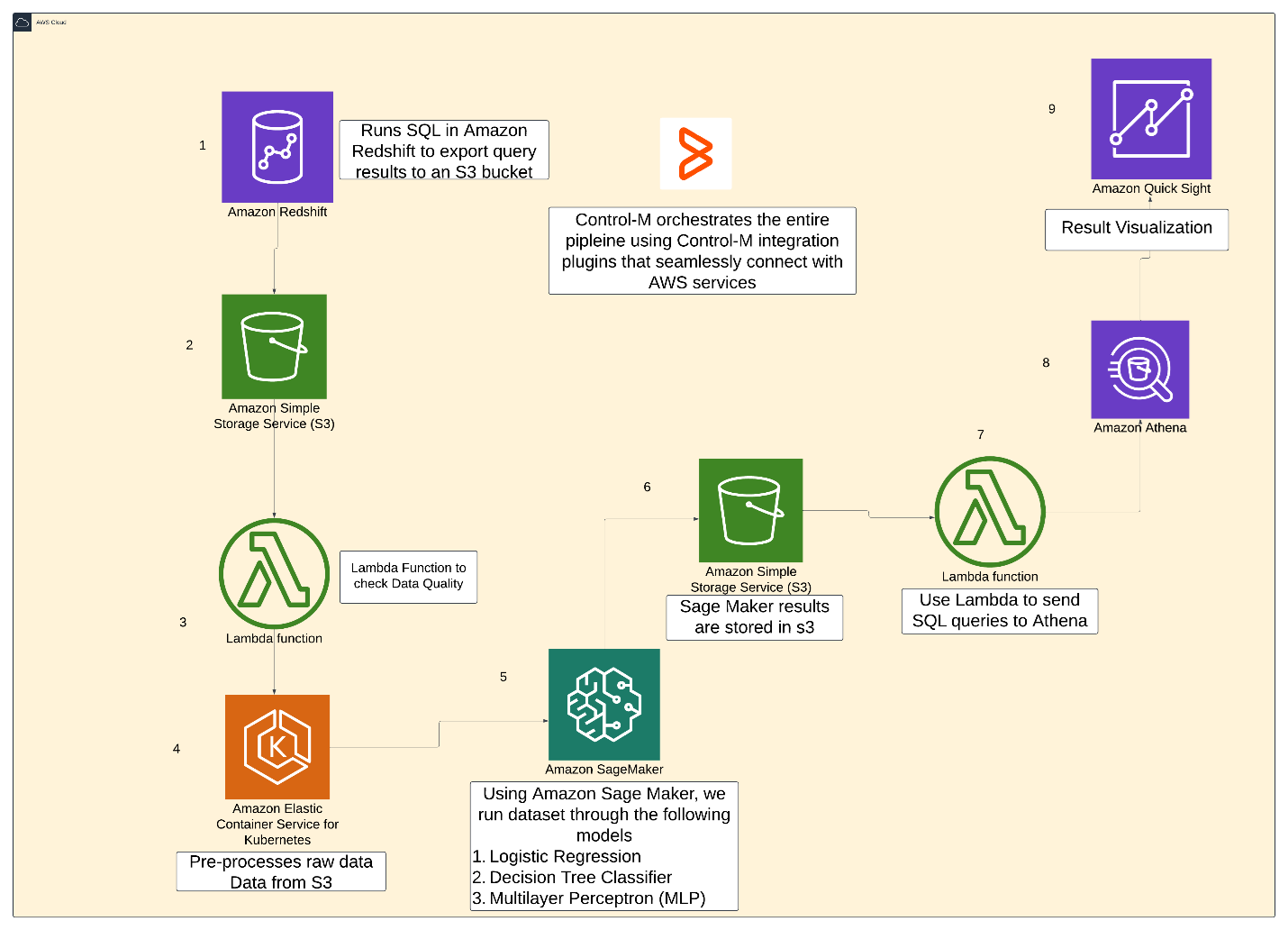
Figure 2. Pipeline archetecture.
Note: All of the code artifacts used are available at this link.
Control-M Integration Plug-ins Used in This Architecture
To orchestrate this analysis pipeline, we leverage Control-M integration plug-ins that seamlessly connect with various platforms and services, including:
-
- Control-M for SageMaker:
- Executes ML model training jobs on Amazon SageMaker.
- Enables integration with SageMaker to trigger training jobs, monitor progress, and retrieve outputs.
- Control-M for Kubernetes:
- Executes Python scripts for data processing and normalization within an Amazon EKS environment.
- Ideal for running containerized jobs as part of the data preparation process.
- Control-M Managed File Transfer:
- Facilitates file movement between Amazon S3 buckets and other storage services.
- Ensures secure and automated data transfers to prepare for analysis.
- Control-M Databases:
- Enables streamlined job scheduling and execution of SQL scripts, stored procedures, and database management tasks across multiple database platforms, ensuring automation and consistency in database operations.
- Control-M for AWS Lambda:
- Enables seamless scheduling and execution of AWS Lambda functions, allowing users to automate serverless workflows, trigger event-driven processes, and manage cloud-based tasks efficiently.
- Ensures orchestration, monitoring, and automation of Lambda functions within broader enterprise workflows, improving operational efficiency and reducing manual intervention
- Control-M for SageMaker:
AWS Services used in this Architecture
- Amazon S3: Amazon S3 is a completely managed Object Storage service.
- Amazon SageMaker: Amazon SageMaker is a fully managed ML service.
- Amazon EKS: Amazon Elastic Kubernetes Service (Amazon EKS) is a fully managed Kubernetes service that enables you to run Kubernetes seamlessly in both AWS Cloud and on-premises data centers.
- Amazon Redshift: Amazon Redshift is a popular Cloud Data Warehouse provided by AWS.
Setting up the Kubernetes environment
The Amazon EKS Kubernetes environment is central to the pipeline’s data preprocessing stage. It runs Python scripts to clean, normalize, and structure the data before it is passed to the ML models. Setting up the Kubernetes environment involves the following steps:
- Amazon EKS Cluster Setup:
- Use Terraform to create an Amazon EKS cluster or set up your Kubernetes environment in any cloud provider.
- Ensure the Kubernetes nodes can communicate with the cluster and vice versa.
- Containerized Python Script:
- Build and push a container image to the Amazon Elastic Container Registry (ECR) for the preprocessing script.
- Deploy a Kubernetes Job to execute the script.
For a detailed guide on setting up a Kubernetes environment for similar workflows, refer to this blog, where we described the Kubernetes setup process step by step.
For a comprehensive walkthrough on setting up Snowflake in similar pipelines, please refer to this blog.
Workflow summary
- Redshift_Unload Job
- Action: Executes a SQL script (copy_into_s3.sql) to extract structured data from Amazon Redshift and store it in Amazon S3.
- Purpose: Moves raw data into an accessible S3 bucket for subsequent transformations.
- Next Step: Triggers S3_to_S3_Transfer to move data from the warehouse bucket to the processing bucket.
- S3_to_S3_Transfer Job
- Action: Uses Control-M’s Managed File Transfer (MFT) to move the dataset from the sam-sagemaker-warehouse-bucket to the bf-sagemaker bucket.
- Purpose: Ensures the data is available in the right location for preprocessing and renames it to Synthetic_Financial_datasets_log.csv.
- Next Step: Triggers the Data_Quality_Check job.
- Data_Quality_Check Job
- Action: Runs an AWS Lambda function (SM_ML_DQ_Test) to validate the dataset.
- Purpose: Ensures the CSV file contains at least 5 columns and more than 1000 rows, preventing corrupt or incomplete data from entering the ML pipeline.
- Next Step: Triggers EKS-Preprocessing-job for data transformation.
- EKS-Preprocessing-Job
- Action: Executes a Kubernetes job to clean and transform the dataset stored in Amazon S3.
- Purpose:
- Runs a Python script (main.py) inside a container to process Synthetic_Financial_datasets_log.csv
- Generates a cleaned and structured dataset (processed-data/output.csv).
- Configuration Details:
- Image: new-fd-repo stored in Amazon ECR
- Environmental variables: Defines S3 input/output file locations
- Resource allocation: Uses 2Gi memory, 1 CPU (scales up to 4Gi memory, 2 CPUs)
- IAM permissions: Uses a Kubernetes service account for S3 access
- Logging & cleanup: Retrieves logs and deletes the job upon completion
- Next step: Triggers the Amazon SageMaker training job.
- Amazon SageMaker_TE_Pipeline
- Action: Runs the TrainingAndEvaluationPipeline in Amazon SageMaker.
- Purpose:
- Trains and evaluates multiple ML models on the preprocessed dataset (processed-data/output.csv).
- Stores trained model artifacts and evaluation metrics in an S3 bucket.
- Ensures automatic resource scaling for efficient processing.
- Next step: Triggers Load_Amazon_Athena_Table to store results in Athena for visualization.
- Load_Amazon_Athena_Table Job
- Action: Runs an AWS Lambda function (athena-query-lambda) to load the evaluation metrics into Amazon Athena.
- Purpose:
- Executes a SQL query to create/update an Athena table (evaluation_metrics).
- Allows QuickSight to query and visualize the model performance results.
How the steps are connected
- Redshift → S3 Transfer: Data is extracted from Amazon Redshift and moved to Amazon S3.
- Data validation and preprocessing: The data quality check ensures clean input before transformation using Kubernetes.
- ML Training: Amazon SageMaker trains and evaluates multiple ML models.
- Athena and QuickSight integration: The model evaluation results are queried through Athena, enabling real-time visualization in Amazon QuickSight.
- Final outcome: A streamlined, automated ML workflow that delivers a trained model and performance insights for further decision-making.
This detailed workflow summary ties each step together while emphasizing the critical roles played by the Kubernetes preprocessing job and the Amazon SageMaker training pipeline.
Control-M workflow definition
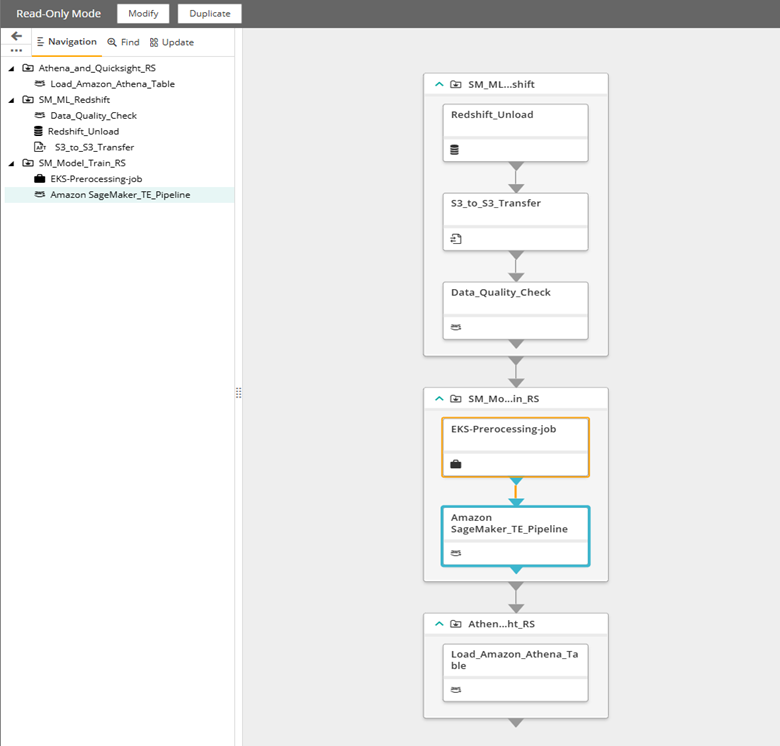
Figure 3. Control-M workflow definition.
In the next section we will go through defining each of these jobs. The jobs can be defined using a drag-and-drop, no-code approach in the Planning domain of Control-M, or they can be defined as code in JSON. For the purposes of this blog, we will use the as-code approach.
Amazon Redshift and file transfer workflows
Redshift_Unload Job
Type: Job:Database:SQLScript
Action: Executes a SQL script in Amazon Redshift to unload data from Redshift tables into an S3 bucket.
Description: This job runs a predefined SQL script (copy_into_s3.sql) stored on the Control-M agent to export structured data from Redshift into Amazon S3. The unloaded data is prepared for subsequent processing in the ML pipeline.
Dependencies: The job runs independently but triggers the Copy_into_bucket-TO-S3_to_S3_MFT-262 event upon successful completion.
Key configuration details: Redshift SQL script execution
SQL script:
UNLOAD ('SELECT * FROM SageTable')
TO 's3://sam-sagemaker-warehouse-bucket/Receiving Folder/Payments_RS.csv'
IAM_ROLE 'arn:aws:iam::xyz:role/jogoldbeRedshiftReadS3'
FORMAT AS csv
HEADER
ALLOWOVERWRITE
PARALLEL OFF
DELIMITER ','
MAXFILESIZE 6GB; -- 1GB max per file
Event handling
- Events to trigger:
- Copy_into_bucket-TO-S3_to_S3_MFT-262 → Signals that the data has been successfully unloaded to S3 and is ready for further processing or transfers.
See an example below:
"Redshift_Unload" : {
"Type" : "Job:Database:SQLScript",
"ConnectionProfile" : "ZZZ-REDSHIFT",
"SQLScript" : "/home/ctmagent/redshift_sql/copy_into_s3.sql",
"Host" : "<<host details>>",
"CreatedBy" : "<<creator’s email>>",
"RunAs" : "ZZZ-REDSHIFT",
"Application" : "SM_ML_RS",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"eventsToAdd" : {
"Type" : "AddEvents",
"Events" : [ {
"Event" : "Copy_into_bucket-TO-S3_to_S3_MFT-262"
} ]
}
}
S3_to_S3_Transfer job
Type: Job:FileTransfer
Action: Transfers a file from one S3 bucket to another using Control-M Managed File Transfer (MFT).
Description: This job moves a dataset (Payments_RS.csv000) from sam-sagemaker-warehouse-bucket to bf-sagemaker, renaming it as Synthetic_Financial_datasets_log.csv in the process. This prepares the data for further processing and validation.
Dependencies: The job waits for Copy_into_bucket-TO-S3_to_S3_MFT-262 to ensure that data has been successfully exported from Redshift and stored in S3 before initiating the transfer.
Key configuration details:
- Source bucket: sam-sagemaker-warehouse-bucket
- Source path: /Receiving Folder/Payments_RS.csv000
- Destination bucket: bf-sagemaker
- Destination path: /temp/
- Renamed file: Synthetic_Financial_datasets_log.csv at the destination.
- Connection profiles: Uses the MFTS3 profile for both the source and destination S3 buckets.
- File watcher: Monitors the source file for readiness with a minimum detected size of 200 MB.
Event handling
- Events to wait for:
- Copy_into_bucket-TO-S3_to_S3_MFT-262 → Ensures data has been exported from Redshift to S3 before transferring it to another S3 bucket.
- Events to trigger:
- S3_to_S3_MFT-TO-Data_Quality_Check → Notifies the next step that the dataset is ready for validation.
- SM_ML_Snowflake_copy-TO-SM_Model_Train_copy → Signals the beginning of the model training process using the processed data.
See an example below:
"S3_to_S3_Transfer" : {
"Type" : "Job:FileTransfer",
"ConnectionProfileSrc" : "MFTS3",
"ConnectionProfileDest" : "MFTS3",
"S3BucketNameSrc" : "sam-sagemaker-warehouse-bucket",
"S3BucketNameDest" : "bf-sagemaker",
"Host" : : "<<host details>>",
"CreatedBy" : : "<<creator’s email>>",
"RunAs" : "MFTS3+MFTS3",
"Application" : "SM_ML_RS",
"Variables" : [ {
"FTP-LOSTYPE" : "Unix"
}, {
"FTP-CONNTYPE1" : "S3"
}, {
"FTP-ROSTYPE" : "Unix"
}, {
"FTP-CONNTYPE2" : "S3"
}, {
"FTP-CM_VER" : "9.0.00"
}, {
"FTP-OVERRIDE_WATCH_INTERVAL1" : "0"
}, {
"FTP-DEST_NEWNAME1" : "Synthetic_Financial_datasets_log.csv"
} ],
"FileTransfers" : [ {
"TransferType" : "Binary",
"TransferOption" : "SrcToDestFileWatcher",
"Src" : "/Receiving Folder/Payments_RS.csv000",
"Dest" : "/temp/",
"ABSTIME" : "0",
"TIMELIMIT" : "0",
"UNIQUE" : "0",
"SRCOPT" : "0",
"IF_EXIST" : "0",
"DSTOPT" : "1",
"FailJobOnSourceActionFailure" : false,
"RECURSIVE" : "0",
"EXCLUDE_WILDCARD" : "0",
"TRIM" : "1",
"NULLFLDS" : "0",
"VERNUM" : "0",
"CASEIFS" : "0",
"FileWatcherOptions" : {
"VariableType" : "Global",
"MinDetectedSizeInBytes" : "200000000",
"UnitsOfTimeLimit" : "Minutes"
},
"IncrementalTransfer" : {
"IncrementalTransferEnabled" : false,
"MaxModificationAgeForFirstRunEnabled" : false,
"MaxModificationAgeForFirstRunInHours" : "1"
},
"DestinationFilename" : {
"ModifyCase" : "No"
}
} ],
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"eventsToWaitFor" : {
"Type" : "WaitForEvents",
"Events" : [ {
"Event" : "Copy_into_bucket-TO-S3_to_S3_MFT-262"
} ]
},
"eventsToAdd" : {
"Type" : "AddEvents",
"Events" : [ {
"Event" : "S3_to_S3_MFT-TO-Data_Quality_Check"
} ]
},
"eventsToDelete" : {
"Type" : "DeleteEvents",
"Events" : [ {
"Event" : "Copy_into_bucket-TO-S3_to_S3_MFT-262"
} ]
}
},
"eventsToAdd" : {
"Type" : "AddEvents",
"Events" : [ {
"Event" : "SM_ML_Snowflake_copy-TO-SM_Model_Train_copy"
} ]
}
}
Data_Quality_Check job
Type: Job:AWS Lambda
Action: Executes an AWS Lambda function to perform a data quality check on a CSV file.
Description: This job invokes the Lambda function SM_ML_DQ_Test to validate the structure and integrity of the dataset. It ensures that the CSV file has at least 5 columns and contains more than 1,000 rows before proceeding with downstream processing. The job logs execution details for review.
Dependencies: The job waits for the event S3_to_S3_MFT-TO-Data_Quality_Check, ensuring that the file transfer between S3 buckets is complete before running data validation.
Key configuration details:
- Lambda function name: SM_ML_DQ_Test
- Execution environment:
- Host: Runs on ip-172-31-18-169.us-west-2.compute.internal
- Connection profile: JOG-AWS-LAMBDA
- RunAs: JOG-AWS-LAMBDA
- Validation criteria:
- ✅ The CSV file must have at least 5 columns.
- ✅ The CSV file must contain more than 1,000 rows.
- Logging: Enabled (Append Log to Output: checked) for debugging and validation tracking.
Event handling:
- Events to wait for:
- The job waits for S3_to_S3_MFT-TO-Data_Quality_Check to confirm that the dataset has been successfully transferred and is available for validation.
- Events to delete:
- The event S3_to_S3_MFT-TO-Data_Quality_Check is deleted after processing to ensure workflow continuity and prevent reprocessing.
See an example below:
"Data_Quality_Check" : {
"Type" : "Job:AWS Lambda",
"ConnectionProfile" : "JOG-AWS-LAMBDA",
"Append Log to Output" : "checked",
"Function Name" : "SM_ML_DQ_Test",
"Parameters" : "{}",
"Host" : : "<<host details>>",
"CreatedBy" : : "<<creator’s email>>",
"Description" : "This job performs a data quality check on CSV file to make sure it has at least 5 columns and more than 1000 rows",
"RunAs" : "JOG-AWS-LAMBDA",
"Application" : "SM_ML_RS",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"eventsToWaitFor" : {
"Type" : "WaitForEvents",
"Events" : [ {
"Event" : "S3_to_S3_MFT-TO-Data_Quality_Check"
} ]
},
"eventsToDelete" : {
"Type" : "DeleteEvents",
"Events" : [ {
"Event" : "S3_to_S3_MFT-TO-Data_Quality_Check"
} ]
}
}
Amazon SageMaker: Model training and evaluation workflows
EKS-Preprocessing-Job
Type: Job:Kubernetes
Action: Executes a Kubernetes job on an Amazon EKS cluster to preprocess financial data stored in an S3 bucket.
Description: This job runs a containerized Python script that processes raw financial datasets stored in bf-sagemaker. It retrieves the input file Synthetic_Financial_datasets_log.csv, applies necessary transformations, and outputs the cleaned dataset as processed-data/output.csv. The Kubernetes job ensures appropriate resource allocation, security permissions, and logging for monitoring.
Dependencies: The job runs independently but triggers the sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262 event upon completion, signaling that the processed data is ready for model training in SageMaker.
Key configuration details:
Kubernetes job specification
- Image: 623469066856.dkr.ecr.us-west-2.amazonaws.com/new-fd-repo
- Command execution: Runs the following script inside the container:
bash
CopyEdit
python3 /app/main.py -b bf-sagemaker -i Synthetic_Financial_datasets_log.csv -o processed-data/output.csv
- Environment variables:
- S3_BUCKET: bf-sagemaker
- S3_INPUT_FILE: Synthetic_Financial_datasets_log.csv
- S3_OUTPUT_FILE: processed-data/output.csv
Resource allocation
- Requested resources: 2Gi memory, 1 CPU
- Limits: 4Gi memory, 2 CPUs
- Volume mounts: Temporary storage mounted at /tmp
Execution environment
- Host: Runs on mol-agent-installation-sts-0
- Connection profile: MOL-K8S-CONNECTION-PROFILE for EKS cluster access
- Pod logs: Configured to retrieve logs upon completion (Get Pod Logs: Get Logs)
- Job cleanup: Deletes the Kubernetes job after execution (Job Cleanup: Delete Job)
Event handling:
- Events to trigger:
- sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262 → Signals that the preprocessed data is ready for SageMaker model training.
See an example below:
"EKS-Prerocessing-job" : {
"Type" : "Job:Kubernetes",
"Job Spec Yaml" : "apiVersion: batch/v1\r\nkind: Job\r\nmetadata:\r\n name: s3-data-processing-job\r\nspec:\r\n template:\r\n spec:\r\n serviceAccountName: default # Ensure this has S3 access via IAM\r\n containers:\r\n - name: data-processing-container\r\n image: 623469066856.dkr.ecr.us-west-2.amazonaws.com/new-fd-repo\r\n command: [\"/bin/sh\", \"-c\", \"python3 /app/main.py -b bf-sagemaker -i Synthetic_Financial_datasets_log.csv -o processed-data/output.csv\"]\r\n env:\r\n - name: S3_BUCKET\r\n value: \"bf-sagemaker\"\r\n - name: S3_INPUT_FILE\r\n value: \"Synthetic_Financial_datasets_log.csv\"\r\n - name: S3_OUTPUT_FILE\r\n value: \"processed-data/output.csv\"\r\n resources:\r\n requests:\r\n memory: \"2Gi\"\r\n cpu: \"1\"\r\n limits:\r\n memory: \"4Gi\"\r\n cpu: \"2\"\r\n volumeMounts:\r\n - name: tmp-storage\r\n mountPath: /tmp\r\n restartPolicy: Never\r\n volumes:\r\n - name: tmp-storage\r\n emptyDir: {}\r\n\r\n",
"ConnectionProfile" : "MOL-K8S-CONNECTION-PROFILE",
"Get Pod Logs" : "Get Logs",
"Job Cleanup" : "Delete Job",
"Host" : : "<<host details>>",
"CreatedBy" : : "<<creator’s email>>",
"RunAs" : "MOL-K8S-CONNECTION-PROFILE",
"Application" : "SM_ML_RS",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"eventsToAdd" : {
"Type" : "AddEvents",
"Events" : [ {
"Event" : "sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262"
} ]
}
}
Amazon SageMaker_TE_Pipeline job
Type: Job:Amazon Sagemaker
Action: Executes an Amazon Sagemaker training and evaluation pipeline to train ML models using preprocessed financial data.
Description: This job runs the TrainingAndEvaluationPipeline, which trains and evaluates ML models based on the preprocessed dataset stored in bf-sagemaker. The pipeline automates model training, hyperparameter tuning, and evaluation, ensuring optimal performance before deployment.
Dependencies: The job waits for the event sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262, ensuring that the preprocessing job has completed and the cleaned dataset is available before training begins.
Key configuration details:
- SageMaker pipeline name: TrainingAndEvaluationPipeline
- Execution environment:
- Host: Runs on prodagents
- Connection profile: MOL-SAGEMAKER-CP for SageMaker job execution
- RunAs: MOL-SAGEMAKER-CP
- Pipeline parameters:
- Add parameters: unchecked (defaults used)
- Retry pipeline execution: unchecked (will not automatically retry failed executions)
Event handling:
- Events to wait for:
- sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262 → Ensures that the preprocessed dataset is available before initiating training.
- Events to delete:
- sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262 → Removes dependency once training begins.
- SM_ML_Snowflake-TO-AWS_SageMaker_Job_1 → Cleans up previous event dependencies.
See an example below:
"Amazon SageMaker_TE_Pipeline" : {
"Type" : "Job:AWS SageMaker",
"ConnectionProfile" : "MOL-SAGEMAKER-CP",
"Add Parameters" : "unchecked",
"Retry Pipeline Execution" : "unchecked",
"Pipeline Name" : "TrainingAndEvaluationPipeline",
"Host" : : "<<host details>>",
"CreatedBy" : : "<<creator’s email>>",
"RunAs" : "MOL-SAGEMAKER-CP",
"Application" : "SM_ML_RS",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"eventsToWaitFor" : {
"Type" : "WaitForEvents",
"Events" : [ {
"Event" : "sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262"
} ]
},
"eventsToDelete" : {
"Type" : "DeleteEvents",
"Events" : [ {
"Event" : "sagemaker-preprocessing-job-TO-AWS_SageMaker_Job_1-751-262"
}, {
"Event" : "SM_ML_Snowflake-TO-AWS_SageMaker_Job_1"
} ]
}
}
Load_Amazon_Athena_Table job
Type: Job:AWS Lambda
Action: Executes an AWS Lambda function to load evaluation results into an Amazon Athena table for further querying and visualization.
Description: This job triggers the Lambda function athena-query-lambda, which runs an Athena SQL query to create or update a table containing ML evaluation metrics. The table enables seamless integration with Amazon QuickSight for data visualization and reporting.
Dependencies: The job waits for the event SM_Model_Train_copy-TO-Athena_and_Quicksight_copy, ensuring that the SageMaker training and evaluation process has completed before loading results into Athena.
Key configuration details:
- Lambda function name: athena-query-lambda
- Execution environment:
- Host: Runs on airflowagents
- Connection Profile: JOG-AWS-LAMBDA
- RunAs: JOG-AWS-LAMBDA
- Athena table purpose:
- Stores ML model evaluation results, including accuracy, precision, and recall scores.
- Enables easy querying of performance metrics through SQL-based analysis.
- Prepares data for visualization in Amazon QuickSight.
Event handling:
- Events to wait for:
- SM_Model_Train_copy-TO-Athena_and_Quicksight_copy → Ensures that the SageMaker training and evaluation process has completed before updating Athena.
- Events to delete:
- SM_Model_Train_copy-TO-Athena_and_Quicksight_copy → Cleans up the event dependency after successfully loading data.
See an example below:
"Load_Amazon_Athena_Table" : {
"Type" : "Job:AWS Lambda",
"ConnectionProfile" : "JOG-AWS-LAMBDA",
"Function Name" : "athena-query-lambda",
"Parameters" : "{}",
"Append Log to Output" : "unchecked",
"Host" : "airflowagents",
"CreatedBy" : "[email protected]",
"RunAs" : "JOG-AWS-LAMBDA",
"Application" : "SM_ML_RS",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
}
},
"eventsToWaitFor" : {
"Type" : "WaitForEvents",
"Events" : [ {
"Event" : "SM_Model_Train_copy-TO-Athena_and_Quicksight_copy"
} ]
},
"eventsToDelete" : {
"Type" : "DeleteEvents",
"Events" : [ {
"Event" : "SM_Model_Train_copy-TO-Athena_and_Quicksight_copy"
} ]
}
}
WORKFLOW EXECUTION:
Training and evaluation steps in Amazon SageMaker
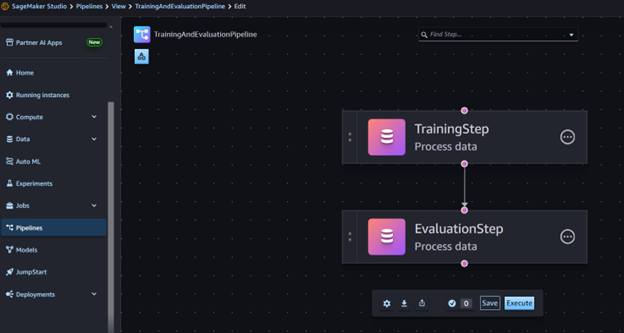
Figure 4. Amazon SageMaker training and evaluation steps.
Pipeline execution logs in CloudWatch:
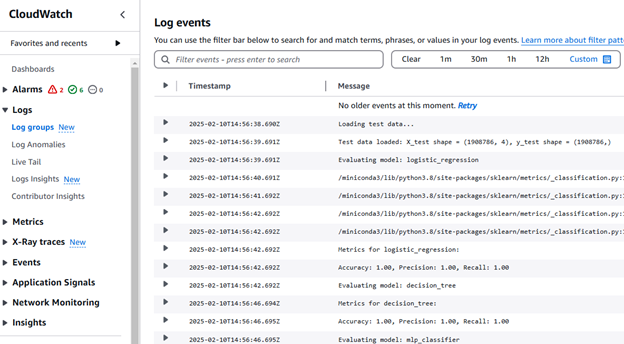
Figure 5. CloudWatch execution logs.
Workflow execution in Control-M
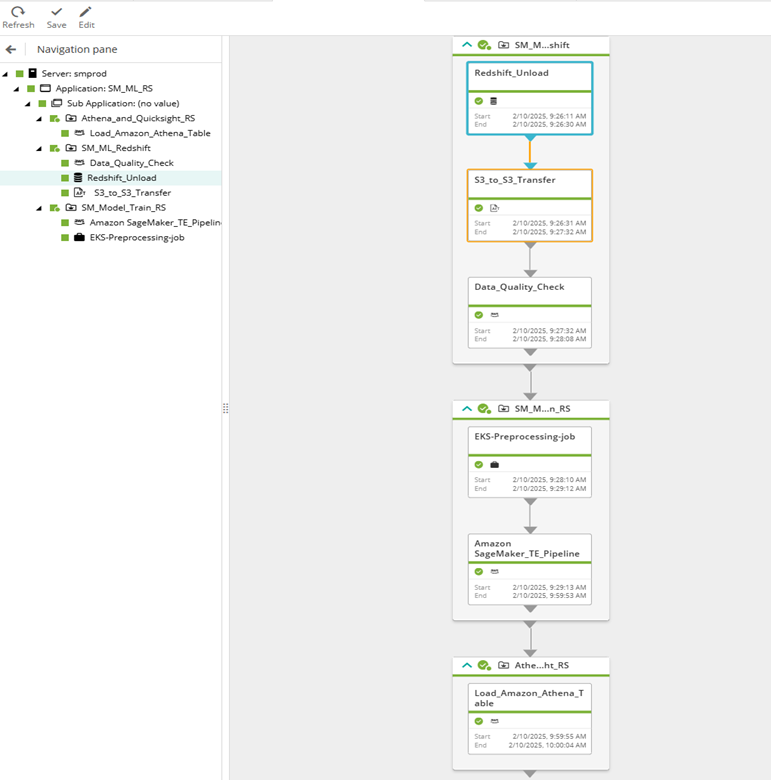
Figure 6. Control-M workflow execution.
The role of Amazon SageMaker:
To analyze the dataset and identify patterns of fraud, we will run the data through three ML models that are available in Amazon SageMaker: logistic regression, decision tree classifier, and multi-layer perceptron (MLP). Each of these models offers unique strengths, allowing us to evaluate their performance and choose the best approach for fraud detection.
- Logistic regression: Logistic regression is a linear model that predicts the probability of an event (e.g., fraud) based on input features. It is simple, interpretable, and effective for binary classification tasks.
- Decision tree classifier: A decision tree is a rule-based model that splits the dataset into branches based on feature values. Each branch represents a decision rule, making the model easy to interpret and well-suited for identifying patterns in structured data.
- Multi-layer perceptron: An MLP is a type of neural network designed to capture complex, non-linear relationships in the data. It consists of multiple layers of neurons and is ideal for detecting subtle patterns that may not be obvious in simpler models.
By running the dataset through these models, we aim to compare their performance and determine which one is most effective at detecting fraudulent activity in the dataset. Metrics such as accuracy, precision, and recall will guide our evaluation.
Trainmodels.py:
This script processes data to train ML models for fraud detection. It begins by validating and loading the input dataset, ensuring data integrity by handling missing or invalid values and verifying the target column isFraud. The data is then split into training and testing sets, which are saved for future use. The logistic regression, decision tree classifier, and MLP are trained on the dataset, with the trained models saved as .pkl files for deployment or further evaluation. The pipeline ensures robust execution with comprehensive error handling and modularity, making it an efficient solution for detecting fraudulent transactions.
Evaluatemodels.py:
This script evaluates ML models for fraud detection using a test dataset. It loads test data and the three pre-trained models to assess their performance. For each model, it calculates metrics such as accuracy, precision, recall, classification report, and confusion matrix. The results are stored in a JSON file for further analysis. The script ensures modularity by iterating over available models and robustly handles missing files or errors, making it a comprehensive evaluation pipeline for model performance.
Results and outcomes
Model evaluation results in Amazon QuickSight.
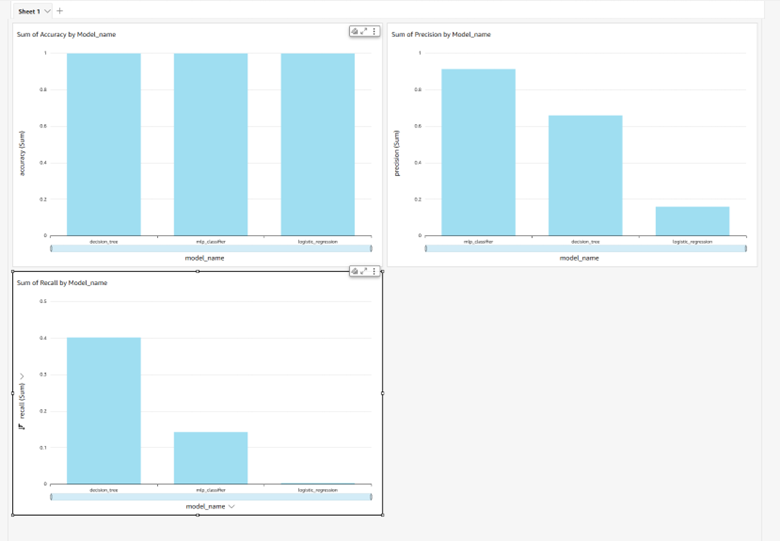
Model evaluation results in Amazon QuickSight
The decision tree classifier model shows the most balanced performance with respect to precision and recall, followed by the MLP. Logistic regression performs poorly in correctly identifying positive instances despite its high accuracy.
Summary
Building an automated, scalable, and efficient ML pipeline is essential for combating fraud in today’s fast-evolving financial landscape. By leveraging AWS services like Amazon SageMaker, Redshift, EKS, and Athena, combined with Control-M for orchestration, this fraud detection solution ensures seamless data processing, real-time model training, and continuous monitoring.
A key pillar of this workflow is Amazon SageMaker, which enables automated model training, hyperparameter tuning, and scalable inference. It simplifies the deployment of ML models, allowing organizations to train and evaluate multiple models—logistic regression, decision tree classifier, and MLP—to determine the most effective fraud detection strategy. Its built-in automation for training, evaluation, and model monitoring ensures that fraud detection models remain up-to-date, adaptive, and optimized for real-world transactions.
The importance of automation and orchestration cannot be overstated—without it, maintaining a production-grade ML pipeline for fraud detection would be cumbersome, inefficient, and prone to delays. Control-M enables end-to-end automation, ensuring smooth execution of complex workflows, from data ingestion to model training in Amazon SageMaker and evaluation in Athena. This reduces manual intervention, optimizes resource allocation, and improves overall fraud detection efficiency.
Moreover, model training and evaluation remain at the heart of fraud detection success. By continuously training on fresh transaction data within Amazon SageMaker, adapting to evolving fraud patterns, and rigorously evaluating performance using key metrics, organizations can maintain high fraud detection accuracy while minimizing false positives.
As fraudsters continue to develop new attack strategies, financial institutions and payment processors must stay ahead with adaptive, AI-driven fraud detection systems. By implementing a scalable and automated ML pipeline with Amazon SageMaker, organizations can not only enhance security and reduce financial losses but also improve customer trust and transaction approval rates.
]]>
We live in a time where technology advancement occurs at a breakneck pace. With each new technology added to the tech stack, complexity increases and environments evolve. Additionally, IT teams are expected to deliver business services in production faster, with quick and effortless problem remediation or, ideally, proactive problem identification. All this can make it extremely challenging for IT to keep up with the demands of the business while maintaining forward progress. That, in turn, can make it increasingly critical for IT executives to find, train, and retain highly qualified IT staff.
Jett, the newest Control-M SaaS capability, is a generative artificial intelligence (GenAI)-powered advisor that revolutionizes the way users interact with the Control-M SaaS orchestration framework. Control-M SaaS users from across the business can ask a wide range of workflow-related questions in their own language and in their own words and quickly receive easy-to-understand graphical and tabular results with a concise text summary. Jett provides the knowledge required to keep business running smoothly. It is a game changer for IT operations (ITOps) teams, allowing them to accelerate troubleshooting, problem resolution, and compliance verification, proactively optimize their workflows, and much more.
ITOps professionals, data teams, application owners, and business users can easily get answers relevant to their individual roles and use cases. With Jett, users don’t need to have in-depth Control-M SaaS knowledge or special training. There’s no additional cost, and you can ask up to 50 questions per day.
The tech behind Jett
Jett leverages cutting-edge GenAI technology to power advanced natural language understanding and generate highly accurate, context-aware responses. Amazon Bedrock’s cutting-edge GenAI technology provides seamless access to Anthropic’s Claude Sonnet. Claude Sonnet, a general-purpose AI, pretrained on a vast dataset, has been leveraged as a foundation model (FM) to understand user questions and transform them into SQL queries and then convert query results into meaningful responses, including visual insights and concise summaries of relevant information.
When a user enters an inquiry, Jett utilizes Claude Sonnet to generate SQL queries based on that inquiry and present the results in an intelligent format. It is guided with well-structured prompts to produce the desired results. These prompts instruct Claude Sonnet to:
- Classify questions based on the type of Control-M objects and whether the query requires aggregation or a list.
- Interpret the Control-M SaaS database schema and generate optimized SQL queries.
- Apply guardrails to restrict out-of-scope questions.
- Summarize and present query results in a clear and structured format.
Jett in action
Jett can assist Control-M SaaS users across the organization in finding answers to a multitude of Control-M SaaS workflow questions that speed problem resolution, audit compliance verification, workflow optimization, and anomaly discovery and analysis. While all the information related to these use cases was available before, users would often have to seek it out and compile it manually. With Jett, questions are answered quickly and presented in a usable format.
Here’s an example of questions that can be answered by Jett:
- Resolving problems quickly
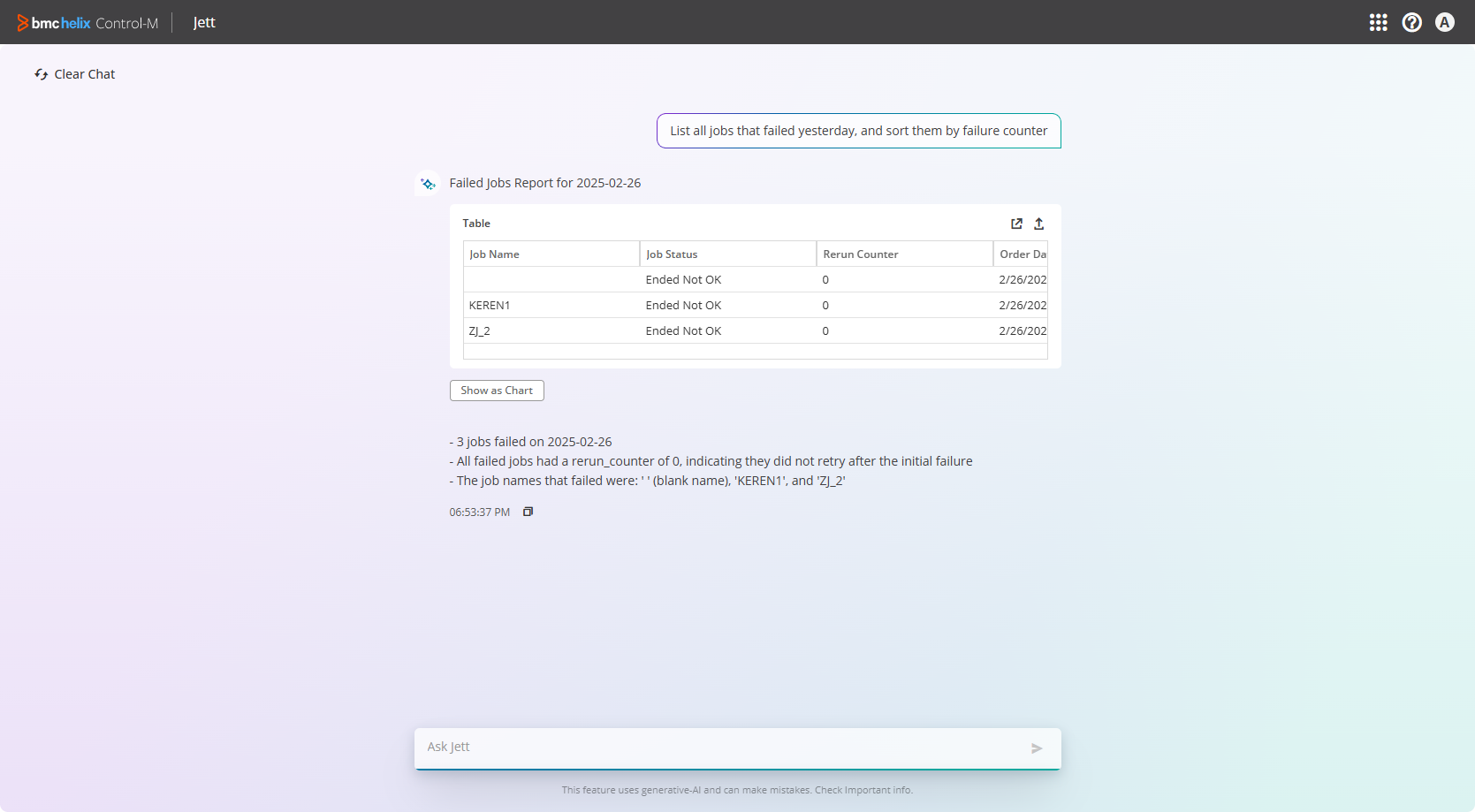
- List all jobs that failed yesterday, and sort them by failure count.
- Has job_1 failed prior to yesterday?
- Analyze the past 10 runs for job_1.
- Faster audit compliance
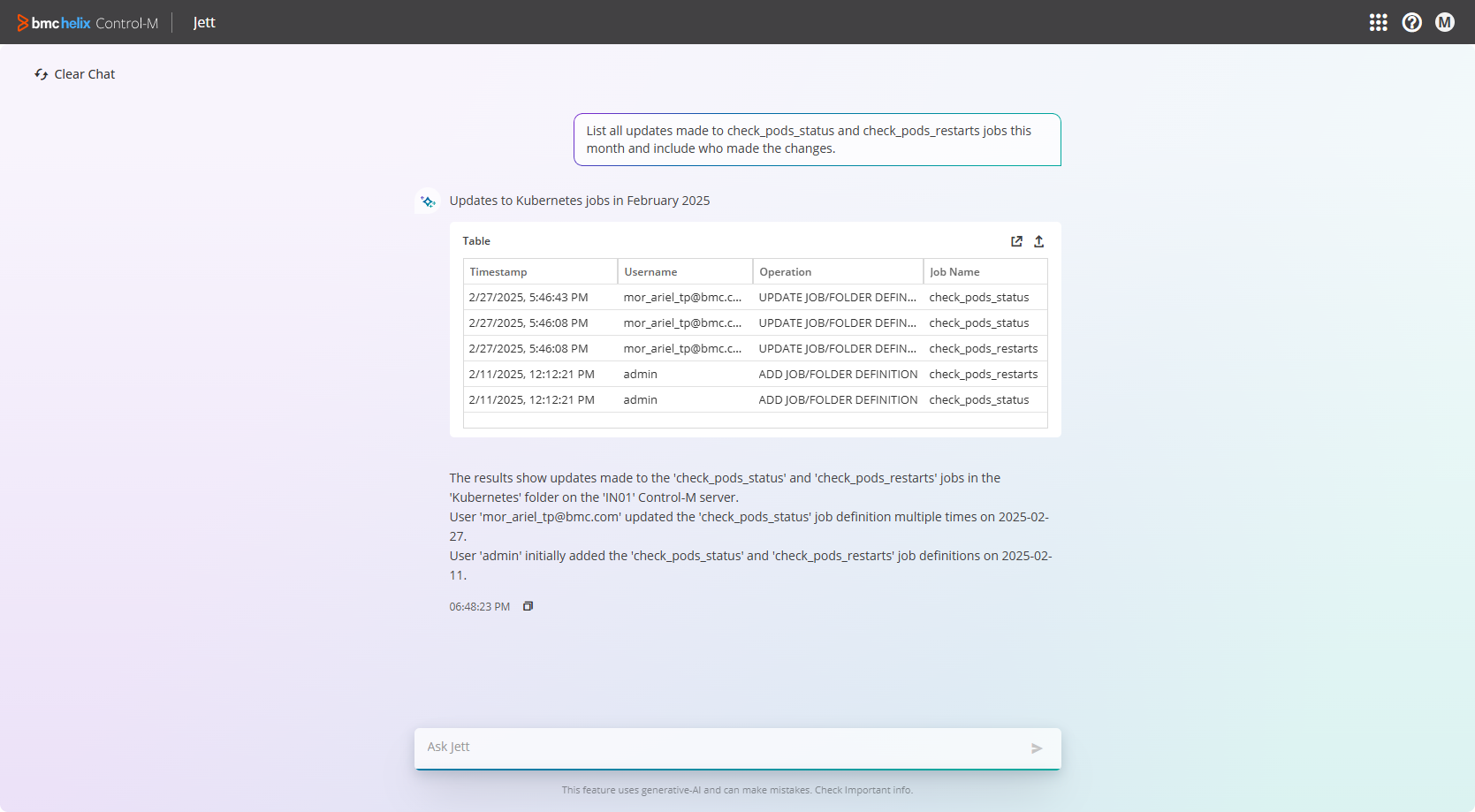
- List all updates made to job_1 this month and include who made the changes.
- Which users made changes to job_1 and application_1, and when were the changes made?
- Optimize workflow performance
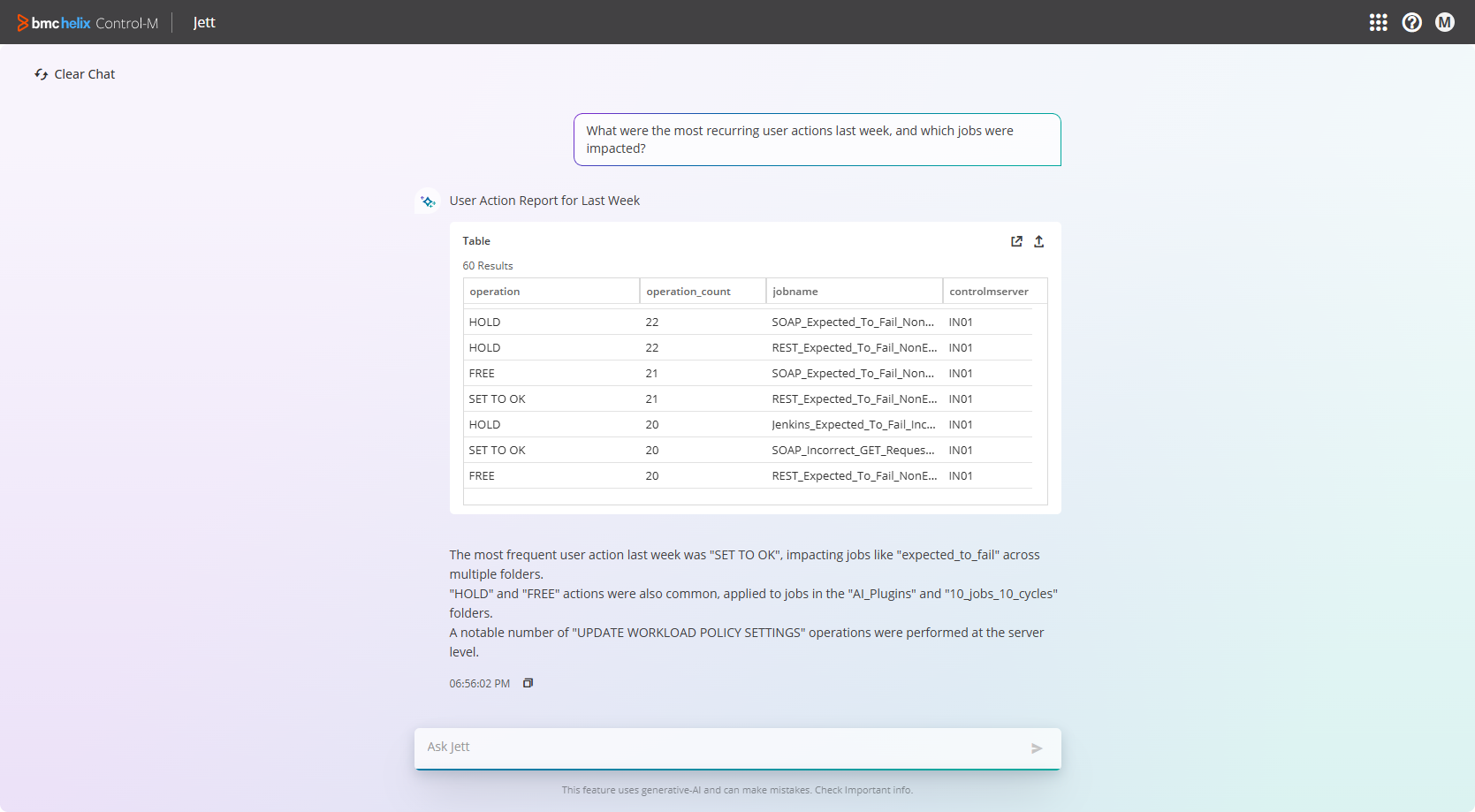
- What were the most recurring user actions last week, and which jobs were impacted?
- Provide all jobs that ran longer than average in the last month.
- Find and analyze anomalies
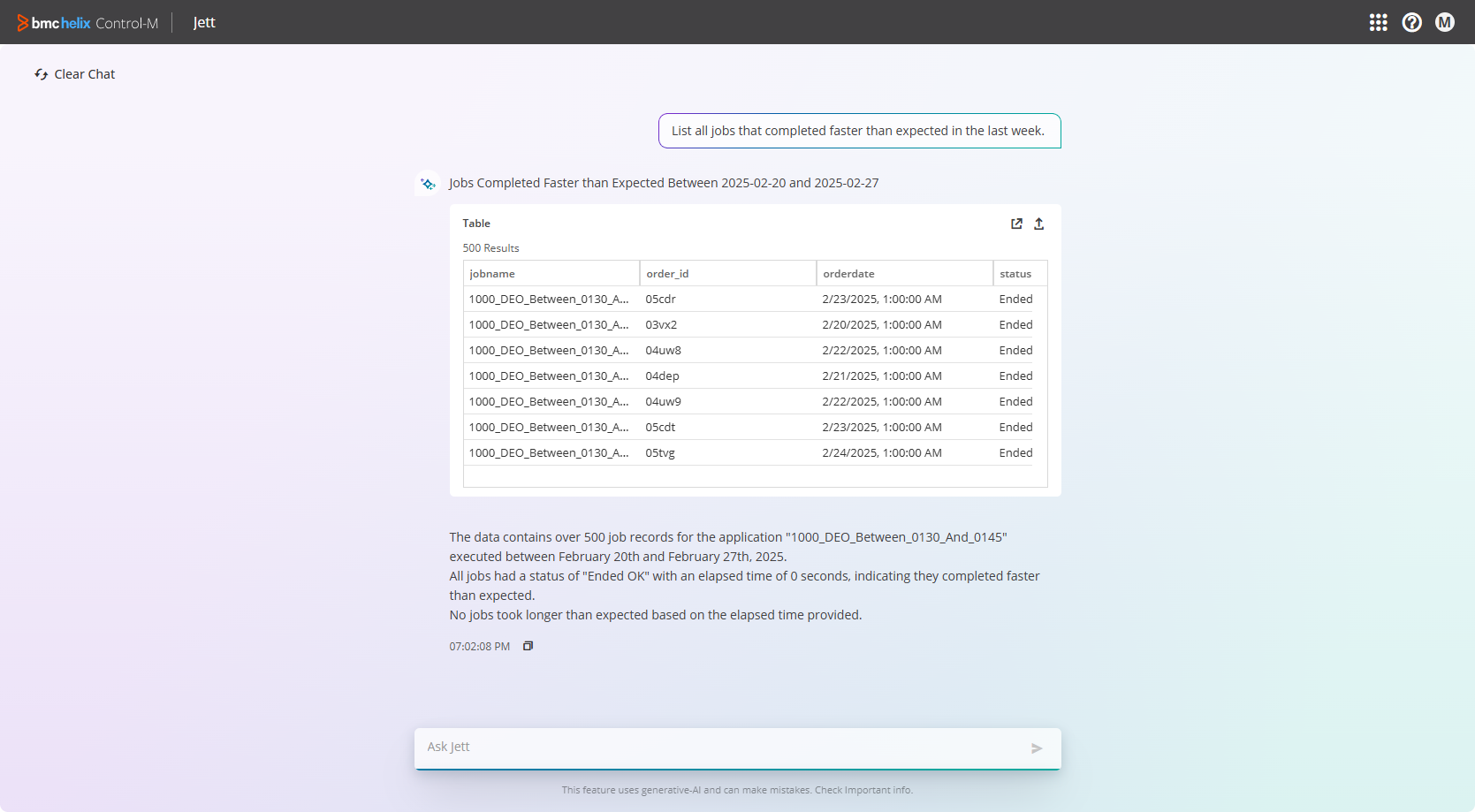
- List all jobs that completed faster than expected in the last week.
- Were there any anomalies in job length over the past month?
Find out how Jett can help you turn valuable time spent on research and internal data collection into time spent on innovation. Contact your Sales or Support rep today!
]]>Workload automation is at a turning point. Once confined to traditional batch processing and job scheduling, it has now become a central driver of digital transformation. The results of the latest Enterprise Management Associates (EMA) Research Report, The Future of Workload Automation and Orchestration, highlight a crucial shift: enterprises are increasingly relying on cloud-driven automation and artificial intelligence (AI)-powered orchestration to navigate modern IT environments.
Cloud adoption is reshaping automation strategies at an unprecedented pace. More organizations are moving their workload automation to cloud-native and hybrid environments, breaking away from rigid, on-premises infrastructures. According to survey results, approximately 30 percent of workload automation (WLA) jobs are run in public clouds and 14 percent are run in hybrid cloud environments. As businesses accelerate cloud migration, the need for seamless application and data workflow orchestration across multiple platforms like Amazon Web Services (AWS), Azure, and Google Cloud, while also ensuring consistency, security, and compliance, has never been greater. Solutions must evolve to not only keep up with this shift but also to proactively streamline cloud operations, offering deep integration and visibility across hybrid ecosystems.
At the same time, AI is redefining the future of orchestration. In fact, 91 percent of survey respondents identify AI-enhanced orchestration as extremely or very important, with 70 percent planning to implement AI-driven capabilities within the next 12 months. The ability to go beyond automation and enable intelligent decision-making is becoming a necessity rather than a luxury. AI-driven orchestration is not just about optimizing job scheduling; it’s also about predicting failures before they occur, dynamically reallocating resources, and enabling self-healing workflows. As organizations integrate AI and machine learning (ML) into their IT and business processes, automation must evolve to support complex data pipelines, MLOps workflows, and real-time data orchestration.
This transformation is not without its challenges. The complexity of managing automation across multi-cloud environments, the growing need for real-time observability, and the increasing role of AI in automation demand a new level of sophistication. Enterprises need solutions that do more than execute tasks—they need platforms that provide visibility, intelligence, and adaptability. The role of workflow orchestration is no longer about keeping the lights on; it is about enabling innovation, agility, and resilience in an era of digital acceleration.
Platform requirements
Clearly, application and data workflow orchestration will continue to be a critical driver, and choosing the right orchestration platform one of the most important decisions a business can make. With that in mind, I’d like to share eight key capabilities a platform must have to orchestrate business-critical workflows in production, at scale.
Heterogeneous workflow support:
Large enterprises are rapidly adopting cloud and there is general agreement in the industry that the future state will be highly hybrid, spanning mainframe to distributed systems in the data center to multiple clouds—private and public. If an application and data workflow orchestration platform cannot handle diverse applications and their underlying infrastructure, then companies will be stuck with many silos of automation that require custom integrations to handle cross platform workflow dependencies.
SLA management:
Business workflows such as financial close and payment settlement all have completion service level agreements (SLAs) governed regulatory agencies. The orchestration platform must be able to understand and notify not only the failures and delays in corresponding tasks, but also be able to link this to business impact.
Error handling and notification:
When running in production, even the best designed workflows will have failures and delays. The orchestrator must enable notifications to the right team at the right time to avoid lengthy war room discussions about assigning a response..
Self-healing and remediation:
When teams respond to job failures within business workflows, they take corrective action, such as restarting something, deleting a file, or flushing a cache or temp table. The orchestrator should allow engineers to configure such actions to happen automatically the next time the same problem occurs, instead stopping a critical workflow while several teams respond to the failures.
End-to-end visibility:
Workflows execute interconnected business processes across hybrid tech stacks. The orchestration platform should be able to clearly show the lineage of the workflows for a better understanding of the relationships between applications and the business processes they support. This is also important for change management, to see what happens upstream and downstream from a process.
Appropriate UX for multiple personas:
Workflow orchestration is a team sport with many stakeholders such as developers, operations teams, and business process owners, etc. Each team has a different use case in how they want to interact with the orchestrator, so it must offer the right user interface (UI) and user experience (UX) for each so they can be effective users of the technology.
Standards in production:
Running in production always requires adherence to standards, which in the case of workflows, means correct naming conventions, error handling patterns, etc. The orchestration platform should be able to provide a very simple way to define such standards and guide users to them when they are building workflows.
Support DevOps practices:
As companies adopt DevOps practices like continuous integration and continuous deployment (CI/CD) pipelines, the development, modification, and even infrastructure deployment of the workflow orchestrator should fit into modern release practices.
EMA’s report underscores a critical reality: the future belongs to organizations that embrace orchestration as a strategic imperative. By integrating AI, cloud automation, and observability into their application and data workflow orchestration strategies, businesses can drive efficiency, optimize performance, and stay ahead of the competition.
To understand the full scope of how workflow orchestration is evolving and what it means for your enterprise, explore the insights from EMA’s latest research.
]]>The Digital Operational Resilience Act (DORA) is a European Union (EU) regulation designed to enhance the operational resilience of the digital systems, information and communication technology (ICT), and third-party providers that support the financial institutions operating in European markets. Its focus is to manage risk and ensure prompt incident response and responsible governance. Prior to the adoption of DORA, there was no all-encompassing framework to manage and mitigate ICT risk. Now, financial institutions are held to the same high risk management standards across the EU.
DORA regulations center around five pillars:
Digital operational resilience testing: Entities must regularly test their ICT systems to assess protections and identify vulnerabilities. Results are reported to competent authorities, with basic tests conducted annually and threat-led penetration testing (TLPT) done every three years.
ICT risk management and governance: This requirement involves strategizing, assessing, and implementing controls. Accountability spans all levels, with entities expected to prepare for disruptions. Plans include data recovery, communication strategies, and measures for various cyber risk scenarios.
ICT incident reporting: Entities must establish systems for monitoring, managing, and reporting ICT incidents. Depending on severity, reports to regulators and affected parties may be necessary, including initial, progress, and root cause analyses.
Information sharing: Financial entities are urged by DORA regulations to develop incident learning processes, including participation in voluntary threat intelligence sharing. Shared information must comply with relevant guidelines, safeguarding personally identifiable information (PII) under the EU’s General Data Protection Regulation (GDPR).
Third-party ICT risk management: Financial firms must actively manage ICT third-party risk, negotiating exit strategies, audits, and performance targets. Compliance is enforced by competent authorities, with proposals for standardized contractual clauses still under exploration.
Introducing Control-M
Financial institutions often rely on a complex network of interconnected application and data workflows that support critical business services. The recent introduction of DORA-regulated requirements has created an urgent need for these institutions to deploy additional tools, including vulnerability scanners, data recovery tools, incident learning systems, and vendor management platforms.
As regulatory requirements continue to evolve, the complexity of managing ICT workflows grows, making the need for a robust workflow orchestration platform even more critical.
Control-M empowers organizations to integrate, automate, and orchestrate complex application and data workflows across hybrid and cloud environments. It provides an end-to-end view of workflow progress, ensuring the timely delivery of business services. This accelerates production deployment and enables the operationalization of results, at scale.
Why Control-M
Through numerous discussions with customers and analysts, we’ve gained valuable insights that reinforce that Control-M embodies the essential principles of orchestrating and managing enterprise business-critical workflows in production at scale.
They are represented in the following picture. Let’s go through, in a bottom-up manner.
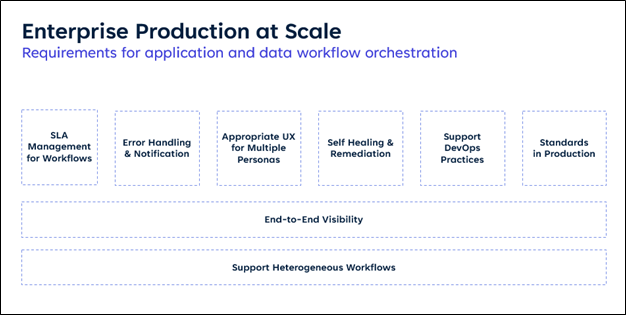
Support heterogeneous workflows
Control-M supports a diverse range of applications, data, and infrastructures, enabling workflows to run across and between various combinations of these technologies. These are inherently hybrid workflows, spanning from mainframes to distributed systems to multiple clouds, both private and public, and containers. The wider the diversity of supported technologies, the more cohesive and efficient the automation strategy, lowering the risk of a fragmented landscape with silos and custom integrations.
End-to-end visibility
This hybrid tech stack can only become more complex in modern business enterprise. Workflows execute interconnected business processes across this hybrid tech stack. Without the ability to visualize, monitor, and manage your workflows end to- end, scaling to production is nearly impossible. Control-M provides clear visibility into application and data workflow lineage, helping you understand the relationships between technologies and the business processes they support.
While the six capabilities at the top of the picture above aren’t everything, they’re essential for managing complex enterprises at scale.
SLA management for workflows
Business services, from financial close to machine learning (ML)-driven fraud detection, all have service level agreements (SLAs), often influenced by regulatory requirements. Control-M not only predicts possible SLA breaches and alerts teams to take actions, but also links them to business impact. If a delay affects your financial close, you need to know it right away.
Error handling and notification
Even the best workflows may encounter delays or failures. The key is promptly notifying the right team and equipping them with immediate troubleshooting information. Control-M delivers on this.
Appropriate UX for multiple personas
Integrating and orchestrating business workflows involves operations, developers, data and cloud teams, and business owners, each needing a personalized and unique way to interact with the platform. Control-M delivers tailored interfaces and superior user experiences for every role.
Self-healing and remediation
Control-M allows workflows to self-heal automatically, preventing errors by enabling teams to automate the corrective actions they initially took manually to resolve the issue.
Support DevOps practices
With the rise of DevOps and continuous integration and continuous delivery (CI/CD) pipelines, workflow creation, modification, and deployment must integrate smoothly into release practices. Control-M allows developers to code workflows using programmatic interfaces like JSON or Python and embed jobs-as-code in their CI/CD pipelines.
Standards in production
Finally, Control-M enforces production standards, which is a key element since running in production requires adherence to precise standards. Control-M fulfills this need by providing a simple way to guide users to the appropriate standards, such as correct naming conventions and error-handling patterns, when building workflows.
Conclusion
DORA takes effect January 17, 2025. As financial institutions prepare to comply with DORA regulations, Control-M can play an integral role in assisting them in orchestrating and automating their complex workflows. By doing so, they can continue to manage risk, ensure prompt incident response, and maintain responsible governance.
To learn more about who Control-M can help your business, visit www.bmc.com/control-m.
]]>Introduction
Integrating Control-M Workload Change Manager with BMC Helix ITSM is a transformative approach that enhances the efficiency and automation of IT change management processes, automates workflows, reduces human intervention, and improves accuracy in managing change processes across workloads in hybrid or multi-cloud environments. BMC Helix ITSM is a leading IT service management platform that helps organizations streamline their service management functions.
Key features of the integration
- Automated change requests: The integration facilitates the automatic real-time creation and status checking of change tasks and requests in BMC Helix ITSM. This helps reduce manual effort and ensures that change management adheres to organizational policies and procedures. Automated workflows can also manage repetitive tasks such as approving or rejecting changes to be implemented in Control-M.
- Real-time monitoring and alerts: The integration enables real-time monitoring of workload changes. Control-M Workload Change Manager monitors workloads across multiple platforms, and any changes trigger notifications or alerts through Control-M, providing full visibility of the infrastructure. This immediate feedback ensures that critical changes are recognized and acted upon promptly.
- Seamless communication: By connecting Control-M Workload Change Manager to BMC Helix ITSM, teams can collaborate more effectively across different departments. Change requests approvals, and status updates are synchronized, ensuring all relevant stakeholders are informed without the need for additional manual communication through “workspace notes.”
- Enhanced compliance and auditability: With automated logging and tracking, all changes made to workloads are documented. This creates an audit trail that can be used to maintain compliance with industry regulations or internal governance policies. Control-M Workload Change Manager ensures that changes adhere to pre-defined policies before they are executed, while BMC Helix ITSM tracks and logs the process.
- Improved change risk assessment: The integration enhances change risk management by providing a clear view of changes. Through historical data and change analytics, the system can evaluate and mitigate risks proactively, reducing the likelihood of disruptions during the change process.
- End-to-end process automation: Control-M Workload Change Manager automates the entire lifecycle of a change request, from initiation and validation to execution and closure. BMC Helix ITSM handles the management and documentation aspects, while Control-M Workload Change Manager ensures that the technical aspects are carried out per the approved plan. This creates a more efficient, end-to-end automated change management process.
- Multi-platform support: The integration supports workload changes across diverse environments, including on-premises infrastructure, cloud environments, or hybrid setups. This flexibility allows organizations to scale their change management operations across different platforms while maintaining centralized control via BMC Helix ITSM.
Benefits
- Increased operational efficiency: Automating change management tasks reduces the time and resources spent on manual processes, allowing IT teams to focus on higher-value tasks.
- Reduced human errors: By automating change processes, the likelihood of human errors decreases, leading to more accurate and reliable implementations.
- Faster change implementation: The integration accelerates the execution of changes, reducing the lead time from request to implementation, improving service delivery, and enhancing business agility.
- Greater visibility and control: IT teams can gain better visibility into the status of workloads and changes across the infrastructure, leading to more informed decision-making and better control over IT operations.
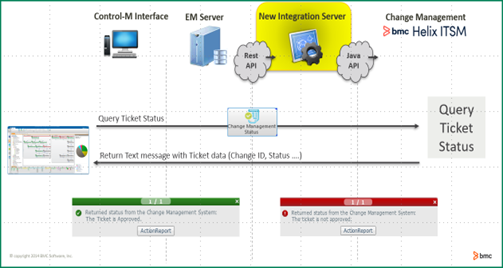
Figure 1. Change request status checking through Control-M.
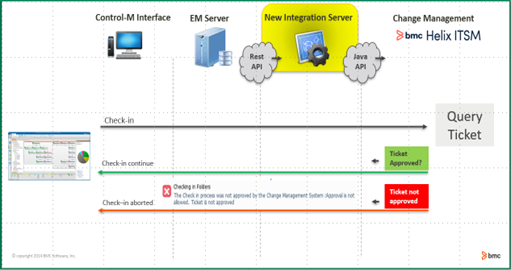
Figure 2. Check-in aborted as the change request is not approved in BMC Helix ITSM.
- Scalability: The combined power of Control-M Workload Change Manager and BMC Helix ITSM allows organizations to scale their change management processes as their infrastructure grows, without a corresponding increase in manual effort or complexity.
- Enhanced collaboration: Communication is facilitated between development, operations, and support teams.
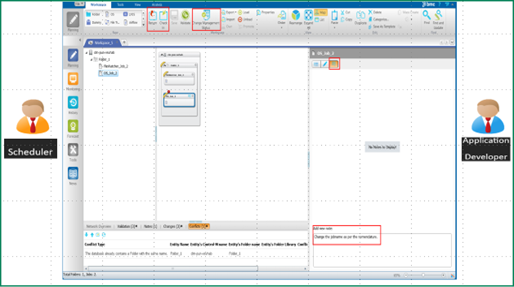
Figure 3. Communication between scheduler and application developer through workspace notes.
Case study
Business challenge:
One of the largest banks in the Asia/Pacific region manages hundreds of job scheduling change requests daily using Control-M Workload Automation. During this process, bank must manually create change requests and check their status in BMC Helix ITSM. Additionally, the scheduling team, responsible for the job scheduling change requests, needs to communicate with the relevant application stakeholders via emails or Teams chat, which often lead to poor tracking of conversations between different teams. The entire process, from creating the change request to verifying the status before implementation, is manual, making it inefficient and time-consuming.
Solution approach:
To address this business challenge and streamline the change management workflow for job scheduling, the bank decides to implement Control-M Workload Change Manager and integrate it with BMC Helix ITSM. This integration helps manage the change workflow in a structured manner, resulting in improved productivity. It also facilitates communication between different stakeholders through workspace notes, making tracking easier, providing real-time status updates, and ensuring that no changes are committed to the Control-M until the change request is approved.
Conclusion
The integration of Control-M Workload Change Manager with BMC Helix ITSM creates a more streamlined, efficient, and reliable approach for managing application workflow changes. It helps organizations minimize downtime, enhance compliance, and improve their overall service management capabilities while delivering a more consistent, automated change management experience. By leveraging this integration, businesses can stay ahead of the dynamic IT landscape, responding to change demands with speed and precision.
]]>Data plays an integral role in the success of modern businesses. In an SAP ecosystem, data must flow from multiple inbound and outbound sources. To make things even more complicated, gathering and processing data, and then delivering insights, often requires orchestration of data and applications across multiple SAP and non-SAP systems. And as companies enact plans to migrate from legacy SAP systems to SAP S/4HANA®, failure of critical SAP data flows can bring those digital transformation and modernization efforts to a screeching halt. Missing business modernization deadlines could have long-lasting ramifications, including additional maintenance costs and less-inclusive approaches.
Without a solid data orchestration strategy to ease the process, SAP data orchestration can get difficult quickly. Orchestrating and monitoring data flow within SAP systems is challenging due to factors like integration complexity, data quality, performance, and scalability issues. Monitoring data workflows through multiple SAP and non-SAP systems can also create a range of difficulties, from a general lack of workflow visibility to the inability to address dataflow failures in a timely manner. In addition, SAP data engineers must manage complex environments with multiple integrations and interoperability, often while trying to keep up with frequent changes in business requirements and technologies. All this work, and the troubleshooting required to find data and job failures, leads to more time and money spent to get everything back on track.
How Control-M Can Help
Control-M (self-hosted and SaaS) provides the workflow orchestration capabilities to help organizations streamline their SAP dataflows in parallel with their migration to SAP S/4HANA. As an SAP-certified solution, Control-M creates and manages SAP ERP Central Component (ECC), SAP S/4HANA, SAP BW, and data archiving jobs, and supports any application in the SAP ecosystem, eliminating time, complexity, and specialized knowledge requirements. It provides out-of-the-box visibility to all enterprise workflows and their dependencies across SAP and non-SAP source systems and de-risks the transition to SAP S/4HANA.
With unified scheduling and automation of workflows with both SAP and non-SAP systems, Control-M can help organizations greatly reduce time to value, complexity, and the requirement for specialized knowledge. It can also be used for all other enterprise jobs, services, processes, and workflows. That lets businesses using SAP build, orchestrate, run, and manage all their enterprise jobs from a consolidated, integrated platform. In addition, Control-M easily adapts to changing business and technology requirements, ensuring that data processes remain consistent across systems and platforms and aligned with organizational goals. And as resources fluctuate, Control-M can help allocate them effectively, optimizing system capability usage and reducing bottlenecks.
Control-M can serve as a comprehensive platform because of its many integrations. The solution can support all SAP versions and job types. It also supports many other enterprise workflows and has more than 100 native integrations with popular tools, including Amazon Web Services (AWS), Azure, and Google Cloud (and many of their components), Oracle, Informatica, SQL, Red Hat, Kubernetes, Apache Airflow, Hadoop, Spark, Databricks, UiPath, OpenText (Micro Focus), Alteryx, and many more.
Conclusion
Robust data orchestration is crucial to the success of your SAP workflows, especially when they include both SAP and non-SAP systems. Complexity can increase quickly, making it difficult to keep up and hard to manage, and, ultimately leading to missed service level agreements (SLAs). With Control-M, organizations can cut through complexity and have full visibility and control of their application and data workflows.
If you’re interested in learning more about how Control-M can help you with SAP dataflows and much more, check out our website, or feel free to reach out to me directly at [email protected]!
]]>According to Gartner, Service Orchestration and Automation Platforms (SOAP) “enable I&O leaders to design and implement business services. These platforms combine workflow orchestration, workload automation and resource provisioning across an organization’s hybrid digital infrastructure.”
The 2024 Gartner® Magic Quadrant™ for Service Orchestration and Automation Platforms (SOAP) is now available. This is the first Gartner Magic Quadrant for SOAP, and we are pleased to announce that BMC has been named a Leader!
As a recognized industry expert, BMC prioritizes customer experience with a commitment to helping organizations maximize the value of our solutions.
“We are delighted to be recognized as a Leader in the inaugural Gartner Magic Quadrant for Service Orchestration and Automation Platforms report. This, we feel, is a testament to our customer relationships and helping them to achieve their evolving business initiatives over many years,” said Gur Steif, president of digital business automation at BMC. “We are continuing to invest in the future of the market focused on AI, data, and cloud innovations and are excited about our customers, our partners, and the opportunities ahead.”
We believe Control-M from BMC and BMC Helix Control-M simplify the orchestration and automation of highly complex, hybrid and multi-cloud applications and data pipeline workflows. Our platforms make it easy to define, schedule, manage and monitor application and data workflows, ensuring visibility and reliability, and improving SLAs.
In addition, BMC Software was recognized in the 2024 Gartner® Market Guide™ for DataOps Tools. As stated in this report, “DataOps tools enable organizations to continually improve data pipeline orchestration, automation, testing and operations to streamline data delivery.”
In the Magic Quadrant for SOAP, Gartner provides detailed evaluations of 13 vendors. BMC is named as a Leader, based on the ability to execute and completeness of vision.
Here’s a look at the quadrant.
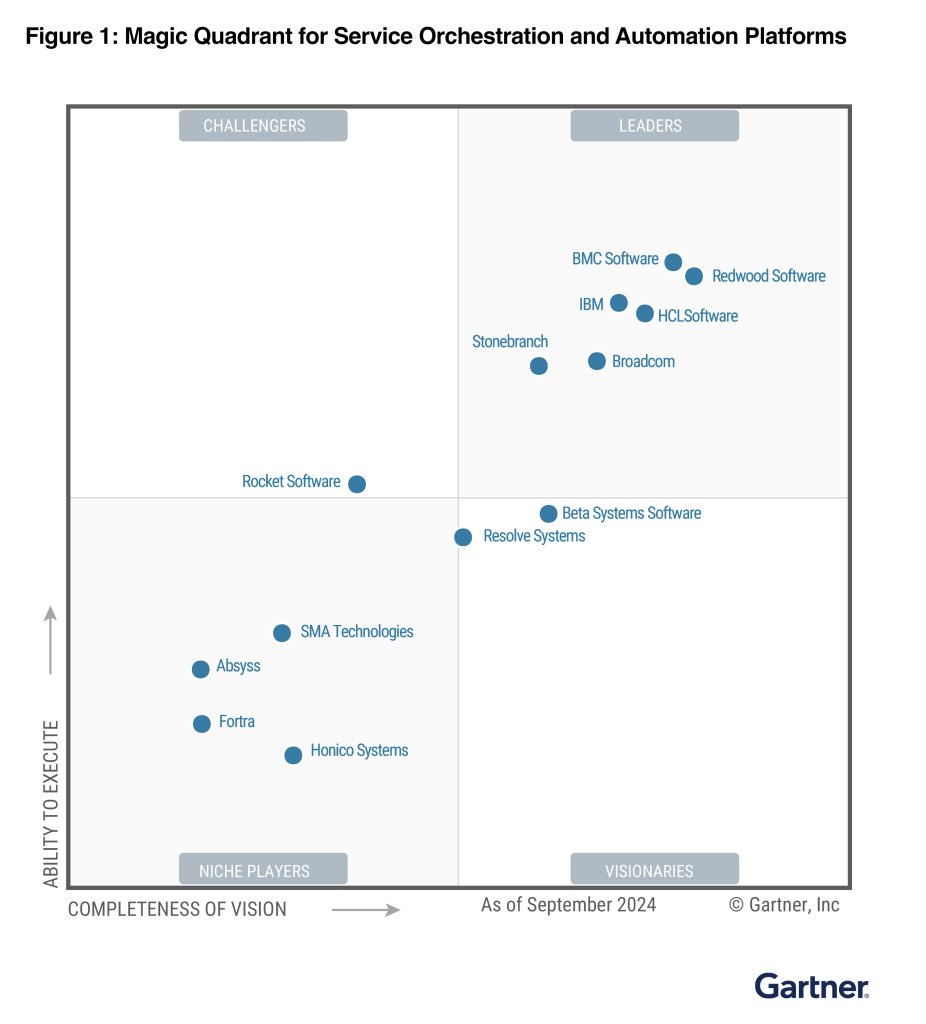
Download the full report to:
- See why BMC was recognized as a Leader for SOAP
- Learn about the latest innovations delivered in the category
Gartner, Magic Quadrant for Service Orchestration and Automation Platforms, by Hassan Ennaciri, Chris Saunderson, Daniel Betts, Cameron Haight, 11 September 2024
Gartner, Market Guide for DataOps Tools, by Michael Simone, Robert Thanaraj, Sharat Menon, 8 August 2024
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from BMC. Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s Research & Advisory organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
]]>SAP’s native job scheduling and monitoring tools, Transaction Codes (t-codes) SM36 and SM37, are fundamental components of many SAP systems. Control-M allows enterprises to get new value from these longtime system staples without requiring resource-intensive redevelopment. This blog explains how.
Individual enterprises may have developed thousands of SM36 and SM37 t-codes to countless servers and SAP instances to help manage the day-to-day tasks that keep SAP systems running. SM36 and SM37 codes clearly have an important place in SAP systems. Sometimes, users tell us that the problem is that the place for SM36 and SM37 is too clearly defined. SM36 and SM37 are system-specific, which means they can only be used to schedule and monitor jobs for the system on which they reside. That works fine for siloed jobs that execute completely within a single server or SAP instance. If the larger workflow needs to break out of that silo, for example to accept a data stream from a cloud-based system or to update a database on another server, then additional SM36 and SM37 codes need to be developed for those systems.
Unless…
…organizations enhance their SM36 and SM37 t-codes through Control‑M (self-hosted or SaaS). The Control-M suite orchestrates workflow execution across the entire enterprise IT environment. It is not system-specific and is widely used to execute highly complex, multi-element workloads across hybrid cloud environments. For SAP users, Control-M provides a complete view of all SAP jobs—and their dependent jobs—across the enterprise. Here’s a deeper look at how Control-M is used with SM36 and 37 to help overcome some of their limitations.
SM36 and SM37 keep systems running
SM36 and SM37 are great tools for scheduling and monitoring the thousands of jobs that run within SAP environments every day. These jobs can include making file transfers, updating databases, running reports, pushing updates to business users, and much more. SM36, SM37, and other t-codes are typically developed in SAP’s Advanced Business Application Programming (ABAP), so responsibility for creating and maintaining them goes to SAP experts, either in-house or at a service provider. As noted, SM36 and SM37 are system-specific. When a file transfer or other job type needs to run on different instances of SAP, or in different versions of SAP, separate t-codes need to be developed for each. If data is handed off from one system to another, or if another workflow similarly crosses different systems, then SM36 and SM37 jobs need to be developed to handle those situations. Such arrangements are standard operating procedure for many enterprises. The process works, although it is a bit resource-intensive and not very transparent.
There are a couple of situations where the skilled resource requirements associated with using SM36 and SM37 have historically caused some problems. One is when there is a job failure or unexplained delay. The other is when the job workflow needs to interact with systems outside of the one where it resides. Let’s look at each of these situations briefly.
SM36 and SM37 job performance problems or outright failures can be difficult to diagnose and debug in complex ecosystems because IT administrators need to look at the logs for all of the associated t-codes in each of the systems that the job touches. Many delays and failures result from one component of a workflow not being ready on time. For example, if a file transfer runs late, the job to run a report that needs data from the file can’t start. Such problems can be solved (prevented) with automated orchestration, but without it, they will need to be manually debugged.
Patch and upgrade installations are other risky periods for job failures. For organizations that use SM36 and SM37, every annual, monthly, and quarterly update or special patch requires manually stopping all inbound and outbound jobs for the upgrade, then restarting them once the update is complete. That’s time-consuming and puts business-critical processes at risk.
As systems become more complex, the chance of workflow failures increases because workflows need to be orchestrated across different systems. How well enterprises can orchestrate workflows depends on how much visibility they have into them. If you can’t see the status of a data stream or other dependent job until after the handoff occurs (or after it fails to occur as scheduled), then you don’t have the visibility you need to prevent failures.
How Control-M can help
Control-M adds the orchestration component to SM36 and SM37 job scheduling and monitoring. It addresses the leading problems associated with those tools by providing visibility across the breadth of the IT environment (helping to foresee and prevent dependency-related job failures) and drill-down depth into the jobs themselves, which enables prevention or fast remediation.
Control-M provides visibility into jobs across the entire SAP ecosystem, regardless of location. If you want to see or change the status of a workflow you go to one place—the Control-M user interface—instead of having to check multiple systems for the status of each step in the workflow. Control-M displays the overall status and gives you the option to drill down and see any dependent job. Users can see the status of an entire workflow with the same or less effort than it takes to do an SM37 check on a single component. That makes managing the SAP environment a lot less resource-intensive.
Here’s an example. System administrators typically investigate SM36 or SM37 job failures by running an ST22 dump analysis. Without Control-M, the logs and short dumps need to be manually intercepted. That procedure takes time and may need to be repeated across multiple SAP instances. Admins don’t need to pull and review logs if they use Control-M because it can automatically monitor logs with no manual intervention required. And, because of Control-M’s ability to automatically monitor all dependencies, a potential problem with one job can be quickly identified and addressed before it affects others. That way, Control-M increases uptime without requiring an increase in administrator support time.
The Italy-based energy infrastructure operator Snam S.p.A. reported it reduced workflow errors by 40 percent after introducing Control-M to its SAP environment, which included SAP ERP Central Component (ECC) and SAP S/4HANA. Freeing up its specialized SAP staff also helped the company improve its business services time to market by 20 percent. You can learn more about the program here.
These are just a few of the ways that orchestrating SM36 and SM37 codes through Control-M reduces complexity and saves time in day-to-day operations. Control-M also provides some other advantages during migrations to SAP S/4HANA or other versions, as this white paper explains.
Control-M is a great complement to SM36 and SM37 because it breaks down silos and works across the entire SAP environment, no matter how complex, and breaks the enterprise’s dependence on a few skilled SAP specialists to manually create and monitor all workflow jobs. Its self-service capabilities enable citizen development in a safe way, where IT retains control over workflows, but business users can handle their own requests. Above all, Control-M creates visibility over all SM36 and SM37 jobs and the entire SAP ecosystem.
]]>Predicting point-of-sale (POS) sales across stores, coordinated with inventory and supply chain data, is table stakes for retailers. This blog explains this use case leveraging PySpark for data and machine learning (ML) pipelines on Databricks, orchestrated with Control-M to predict POS and forecast inventory items. This blog has two main parts. In the first section, we will cover the details of a retail forecasting use case and the ML pipeline defined in Azure Databricks. The second section will cover the integration between Control-M and Databricks.
Developing the use case in Azure Databricks
Note: All of the code used in this blog is available at this github repo.
In real life, data would be ingested from sensors and mobile devices, with near-real-time inventory measurements and POS data across stores. The data and ML pipeline is coordinated with Control-M to integrate the different components and visualize the results in an always-updated dashboard.
The data lands in the Databricks Intelligent Data Platform and is combined, enriched, and aggregated with PySpark Jobs. The resulting data is fed to different predictive algorithms for training and forecasting sales and demand with the results visualized in:
- Graphical dashboards
- Written as delta files to a data repository for offline consumption
In this post, we will also walk through the architecture and the components of this predictive system.
Data set and schema
The project uses real-world data, truncated in size and width to keep things simple. A simplified and abridged version of the schema is shown in Figure 1. The location table is a reference table, obtained from public datasets. The color coding of the fields shows the inter-table dependencies. Data was obtained partially from Kaggle and other public sources.
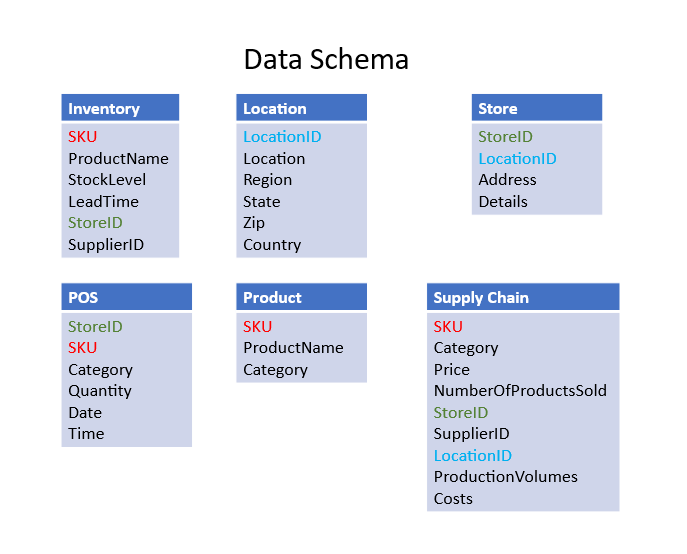
Figure 1. Example of schema.
Platform and components
The following components are used for implementing the use case:
- Databricks Intelligent Data Platform on Azure
- PySpark
- Python Pandas library
- Python Seaborn library for data visualization
- Jupyter Notebooks on Databricks
- Parquet and Delta file format
Project artifacts
- Working environment on Azure
- Code for data ingestion, processing, ML training, and serving and saving forecasted results to Databricks Lakehouse in delta format
- Code for workflow and orchestration with Control-M to coordinate all the activities and tasks and handle failure scenarios
High-level architecture and data flow
Current architecture assumes that data lands in the raw zone of the data lakehouse as a csv file with a pre-defined schema as a batch. The high-level overview of the data flow and associated processes is showed in Figure 2.
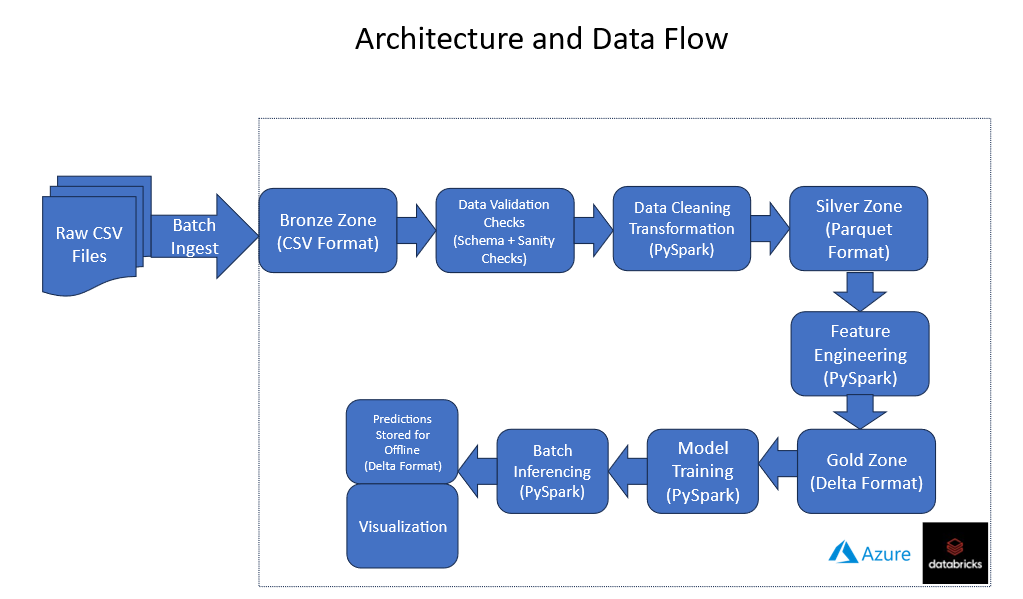
Figure 2. Overview of data flow and associated processes.
Data and feature engineering
Currently the data and ML pipelines are modeled as a batch process. Initial exploratory data analysis (EDA) was done to understand the datasets and relevant attributes contributing to predicting the inventory levels and POS sales. Initial EDA indicated that it is useful to transform the dates to “day of the week”- and “time of day”- type categories for best predictive results. The data pipelines included feature engineering capabilities for datasets that had time as part of the broader dataset.
Figure 3 shows a sample data pipeline for POS dataset. Figure 4 shows another similar data pipeline for an inventory dataset. Post data transformation, the transformed tables were joined to form a de-normalized table for model training. This is shown in Figure 5 for enriching the POS and the inventory data.
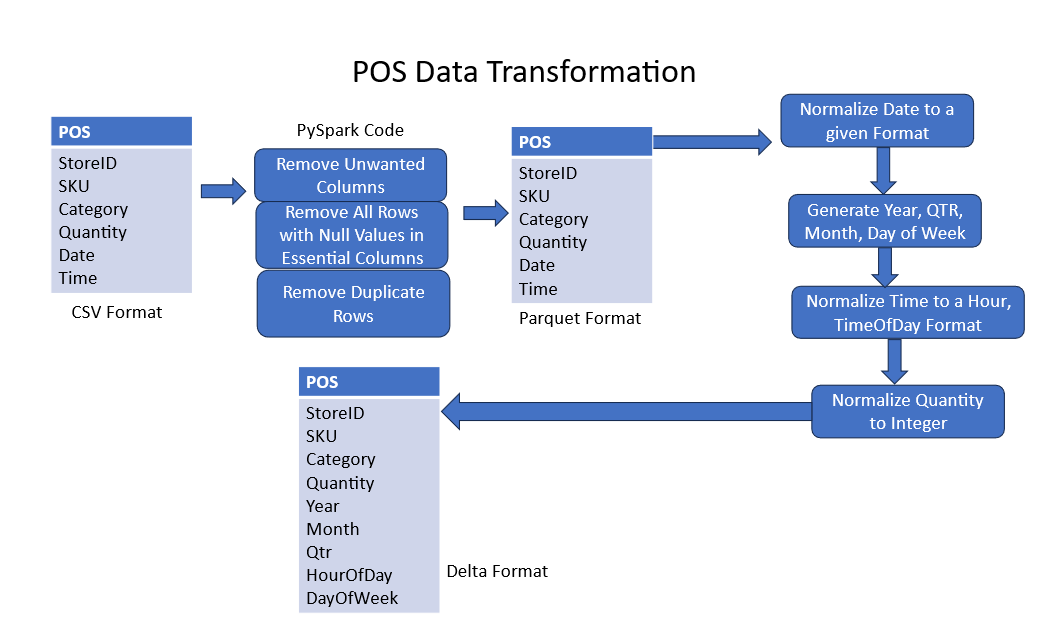
Figure 3. A sample data pipeline for POS dataset.
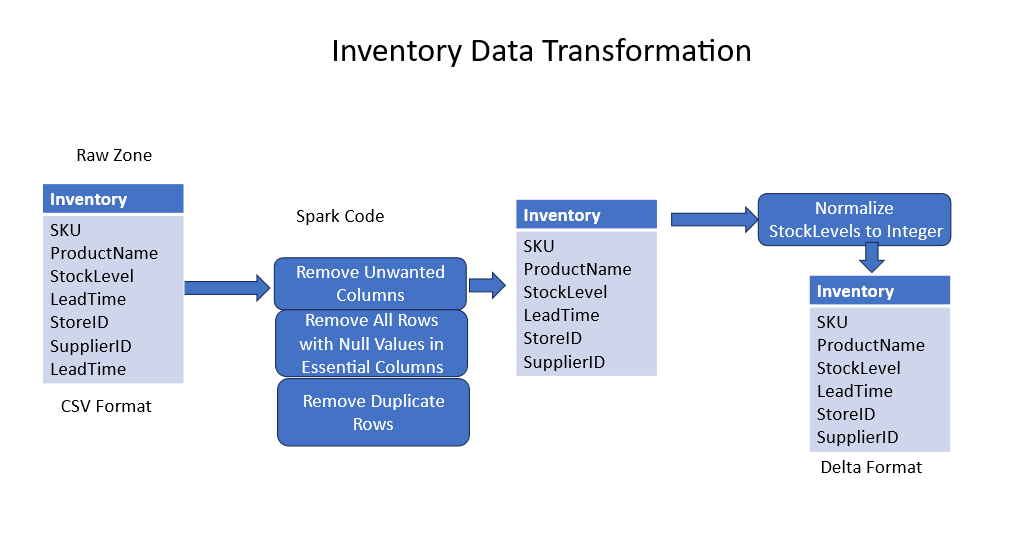
Figure 4. Sample data pipileine for inventory dataset.
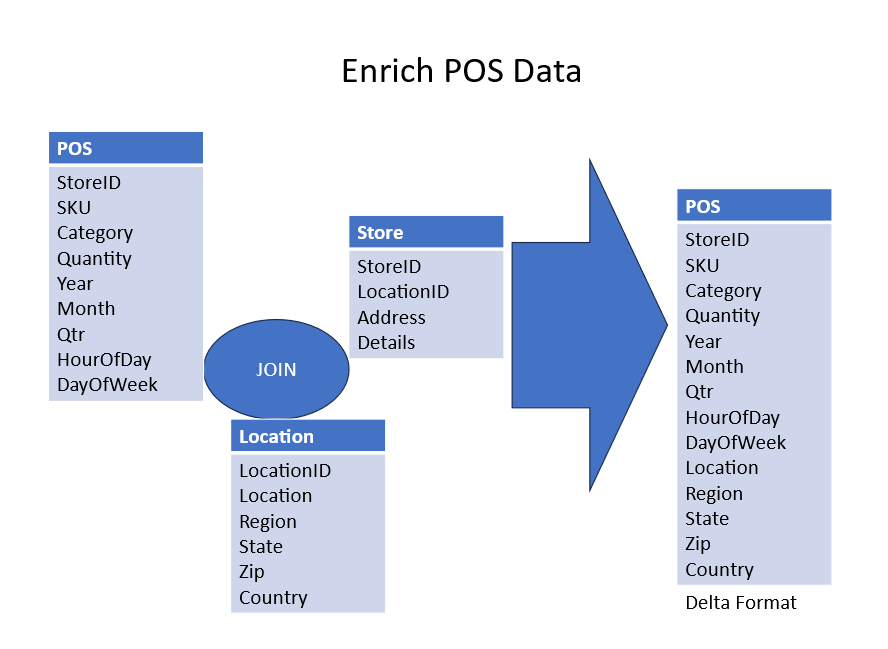
Figure 5. The joining of transformed tables to form a de-normalized table for model training.
Model training
The ML training pipeline used random forest and linear regression to predict the sales and inventory levels. The following modules from PySpark were used to create the ML pipeline and do one-hot encoding on the categorical variables.
- pyspark.ml.Pipeline
- pyspark.ml.feature.StringIndexer, OneHotEncoder
- pyspark.ml.feature.VectorAssembler
- pyspark.ml.feature.StandardScaler
- pyspark.ml.regression.RandomForestRegressor
- pyspark.ml.evaluation.RegressionEvaluator
- pyspark.ml.regression.LinearRegression
The enriched data was passed to the pipelines and the different regressor models were applied to the data to generate the predictions.
The RegressionEvaluator module was used to evaluate the results and the median absolute error (MAE), root mean squared error (RMSE), and R-squared metrics were generated to evaluate the predicted results. Feature weights were used to understand the contribution weights of each of the features to the predictions.
Orchestrating the end-to-end predictions
Data orchestration of the different PySpark notebooks uses a Databricks Workflows job while the production orchestration is performed by Control-M using its Databricks plug-in. This approach enables our Databricks workflow to be embedded into the larger supply chain and inventory business workflows already managed by Control-M for a fully automated, end-to-end orchestration of all related processing. Furthermore, it gives us access to advanced scheduling features like the ability to manage concurrent execution of multiple Databricks workflows that may require access to constrained shared resources such as public IP addresses in our Azure subscription.
Figure 6 shows the different orchestrated tasks to generate the offline predictions and dashboard. The orchestration was kept simple and does not show all the error paths and error handling paths.
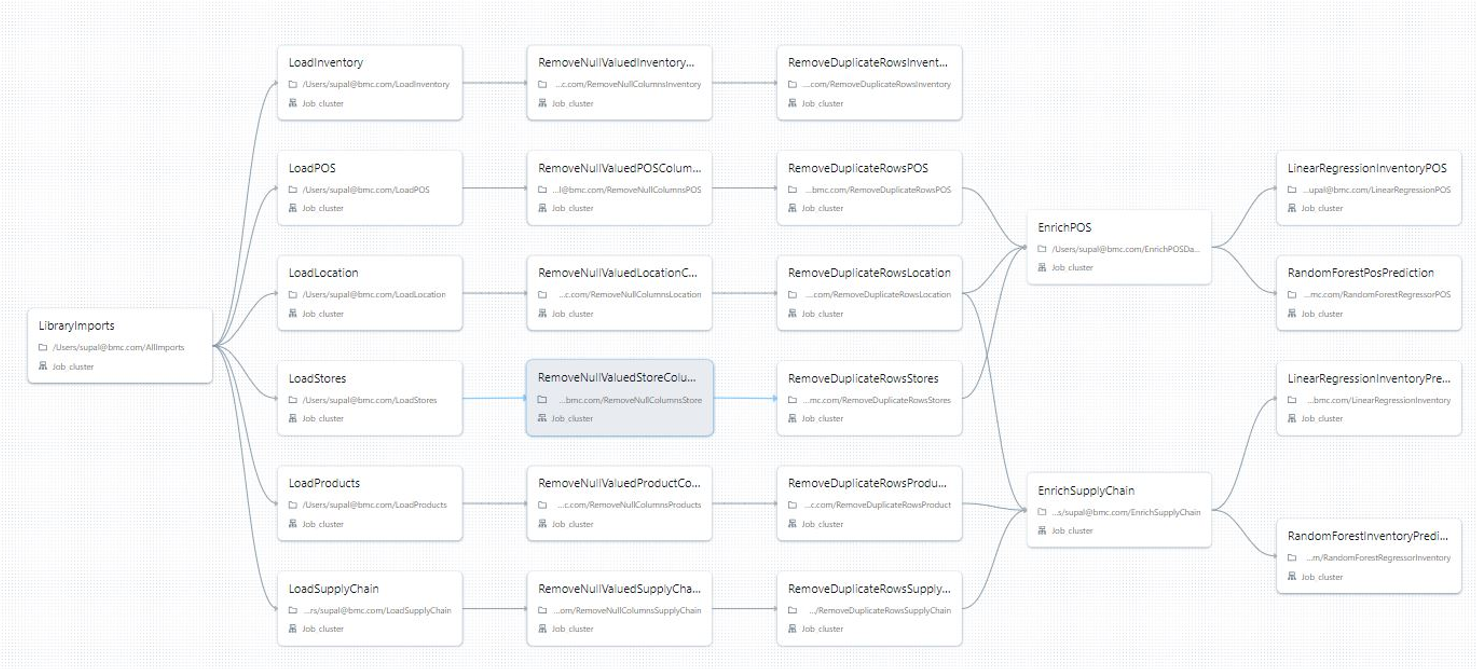
Figure 6. The different orchestrated tasks to generate the offline predictions and dashboard.
Control-M Integration with Databricks
Before creating a job in Control-M that can execute the Databricks workflow, we will need to create a connection profile. A connection profile contains authorization credentials—such as the username, password, and other plug-in-specific parameters—and enables you to connect to the application server with only the connection profile name. Connection profiles can be created using the web interface and then retrieved in json format using Control-M’s Automation API. Included below is a sample of the connection profile for Azure Databricks in json format. If you create the connection profile directly in json before running the job, it should be deployed using the Control-M Automation API CLI.
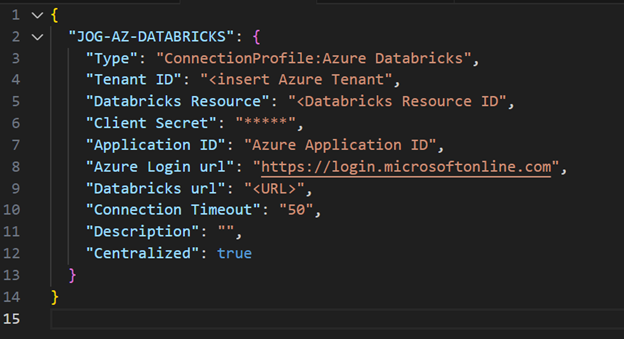
Creating a Databricks job
The job in Control-M that will execute the Databricks workflow is defined in json format as follows:
{
"jog-databricks" : {
"Type" : "Folder",
"ControlmServer" : "smprod",
"OrderMethod" : "Manual",
"SiteStandard" : "jog",
"SubApplication" : "Databricks",
"CreatedBy" : "[email protected]",
"Application" : "jog",
"DaysKeepActiveIfNotOk" : "1",
"When" : {
"RuleBasedCalendars" : {
"Included" : [ "EVERYDAY" ],
"EVERYDAY" : {
"Type" : "Calendar:RuleBased",
"When" : {
"DaysRelation" : "OR",
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ]
}
}
}
},
"jog-azure-databricks-workflow" : {
"Type" : "Job:Azure Databricks",
"ConnectionProfile" : "JOG-AZ-DATABRICKS",
"Databricks Job ID" : "674653552173981",
"Parameters" : "\"params\" : {}",
"SubApplication" : "Databricks",
"Host" : "azureagents",
"CreatedBy" : "[email protected]",
"RunAs" : "JOG-AZ-DATABRICKS",
"Application" : "jog",
"When" : {
"WeekDays" : [ "NONE" ],
"MonthDays" : [ "ALL" ],
"DaysRelation" : "OR"
},
"AzEastPublicIPs" : {
"Type" : "Resource:Pool",
"Quantity" : "8"
}
}
}
}
Running the Databricks workflow
To run the job we will use the run service within Automation API.

Visualizing the workflow
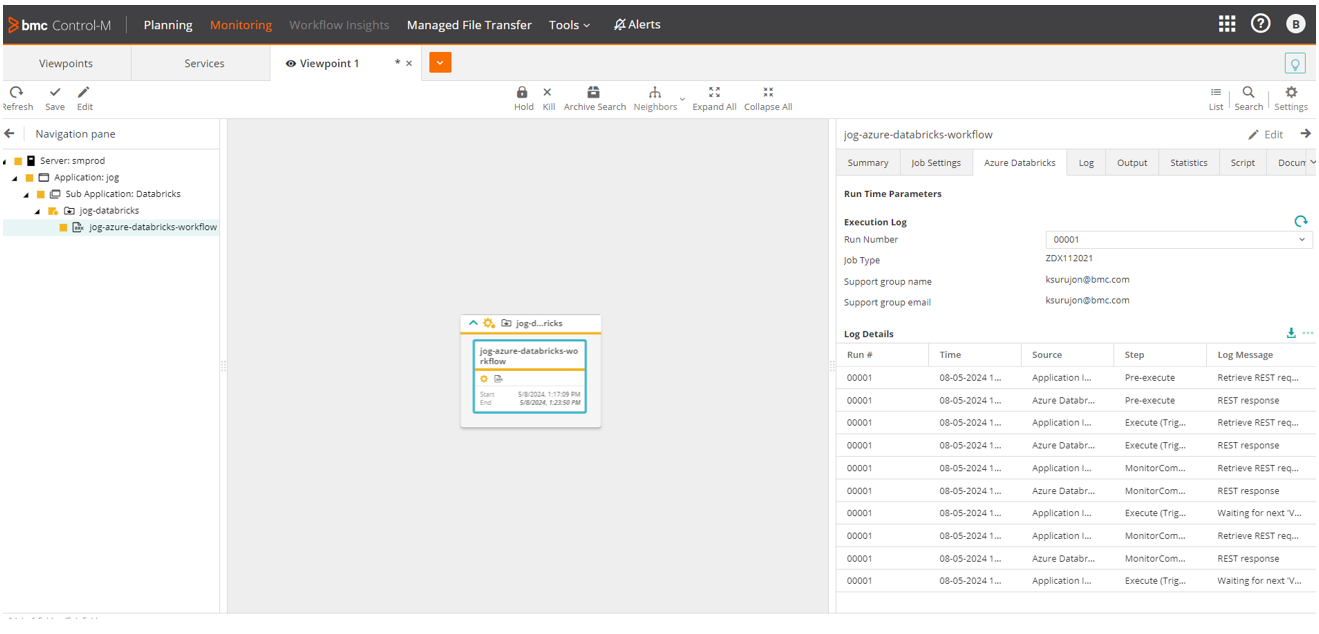
Figure 7. Databricks workflow executing in the Control-M monitoring domain.
Output of completed Databricks job in Control-M
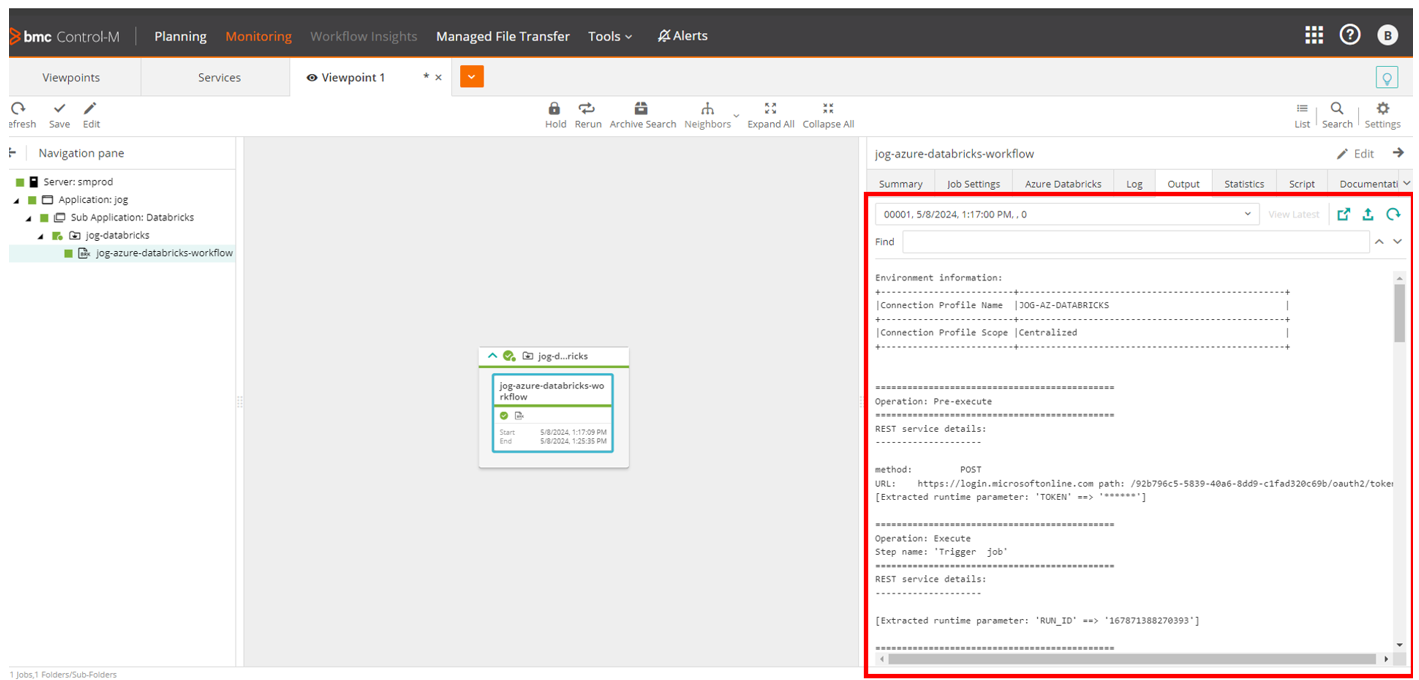
Figure 8. Output of completed Databricks job in Control-M.
Task workflow in Azure Databricks
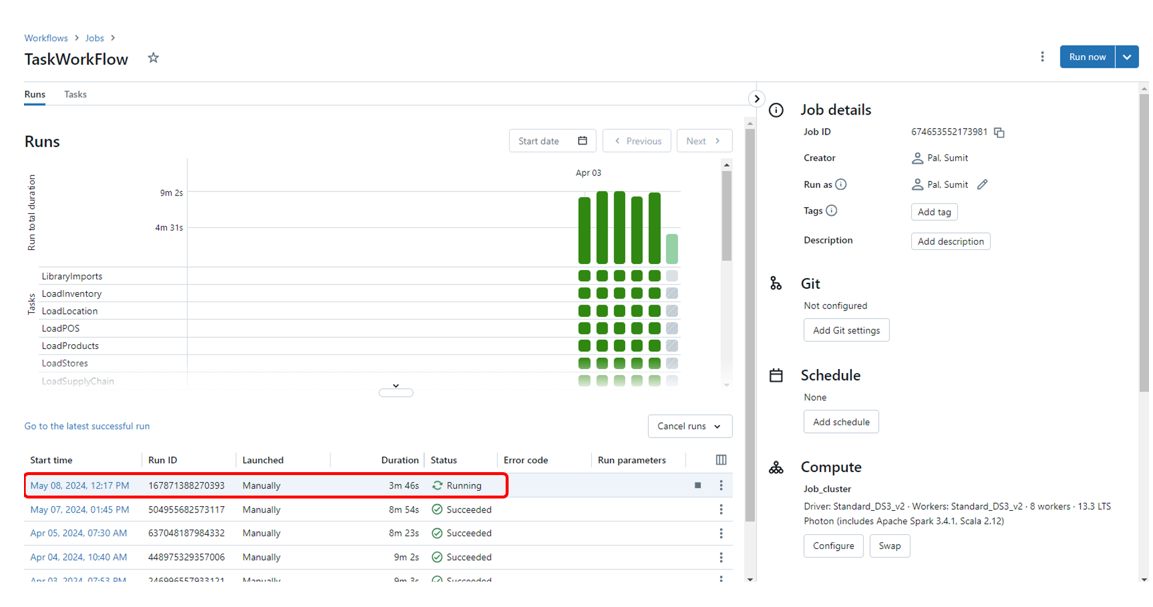
Figure 9. Task workflow in Azure Databricks.
Graph view of task workflow in Azure Databricks

Figure 10. Graph view of task workflow in Azure Databricks.
Outputs and visualization
Two forms of output were generated during the project.
- Predicted results from the model for POS sales and inventory predictions needed based on demand—these were stored as Delta format files on the lakehouse for offline viewing and analysis.
- Visualizations of the feature weights that contributed to the predictions for POS and inventory data for both random forest and linear regression algorithms.
The four figures below show the feature weights for each of the above algorithms across the different features for POS and inventory predictions from the feature engineered attributes.
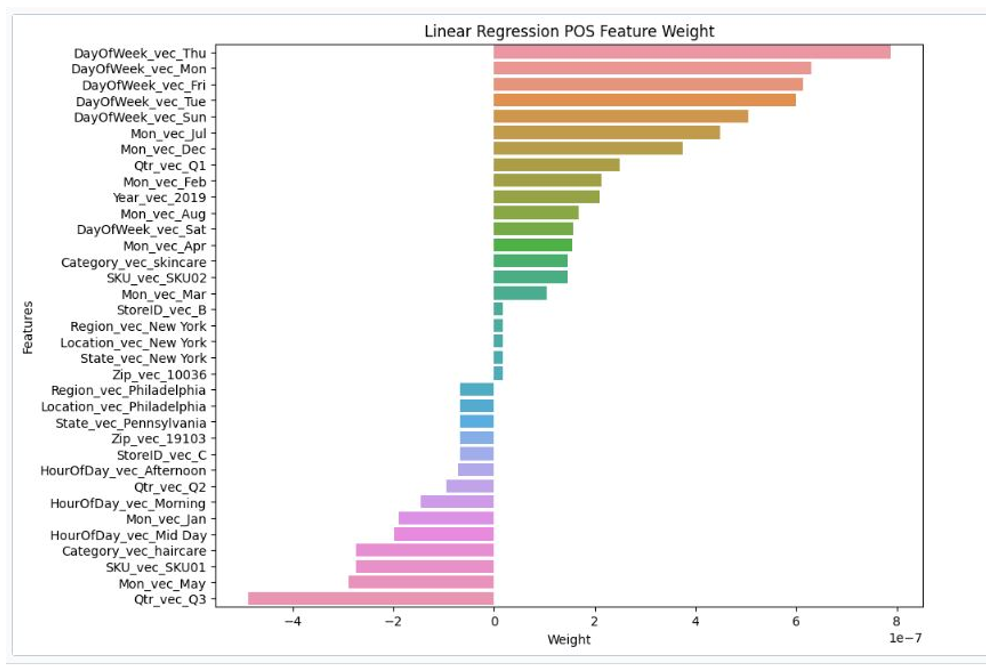
Figure 11. Linear regression POS feature weight.
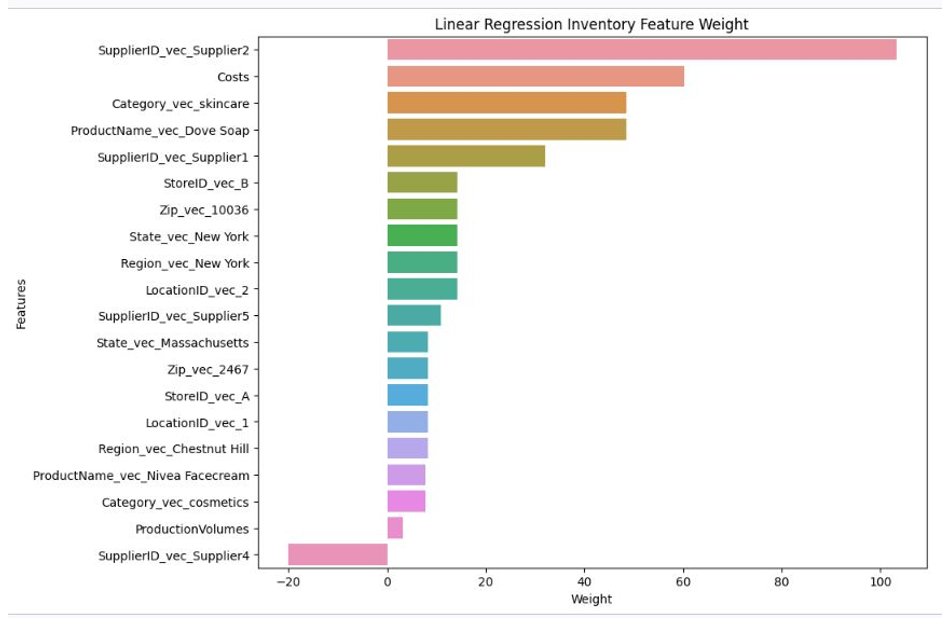
Figure 12. Linear regression inventory feature weight.
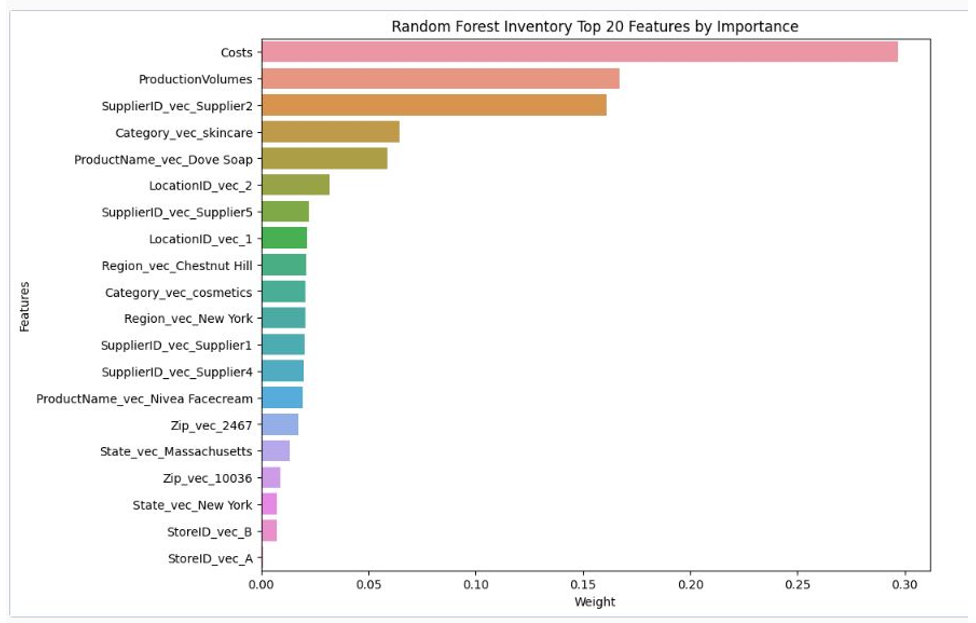
Figure 13. Random forest inventory top 20 features by importance.
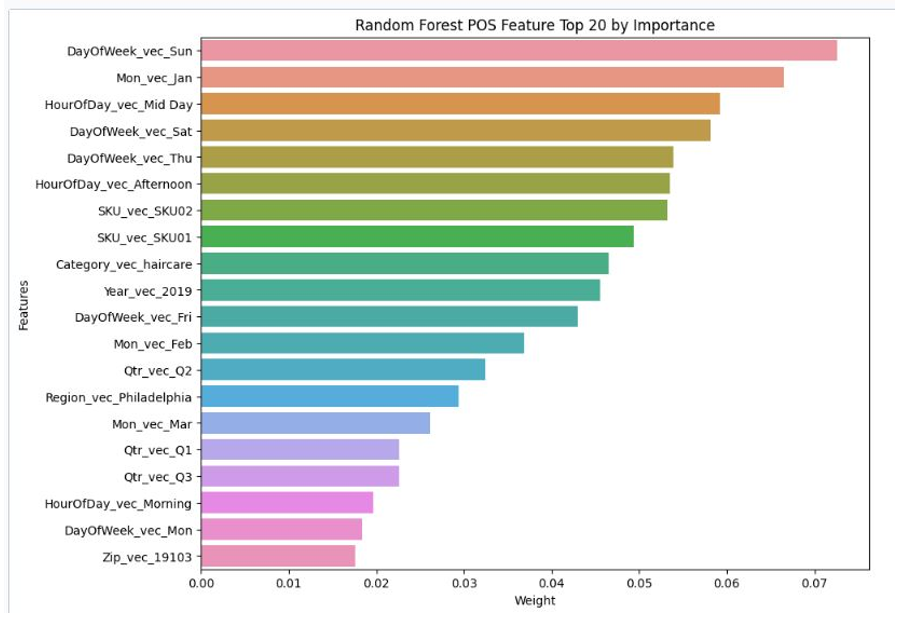
Figure 14. Random forest POS feature top 20 by importance.
Conclusion
This blog demonstrates an ML use case for forecasting of sales and inventory. The ML workflow is likely to be part of a larger orchestration workflow in Control-M. where it is interdependent on workflows running in POS and inventory management applications. However, in this blog, we have maintained the focus on the ML workflow in Databricks and its integration and execution through Control-M.
]]>